
This document is relevant for: Inf2, Trn1
NeuronCore-v2 Architecture#
NeuronCore-v2 is the second generation of the NeuronCore engine, powering the Trainium chips. Each NeuronCore-v2 is a fully-independent heterogenous compute-unit, with 4 main engines (Tensor/Vector/Scalar/GPSIMD Engines), and on-chip software-managed SRAM memory, for maximizing data locality (compiler managed, for maximum data locality and optimized data prefetch).
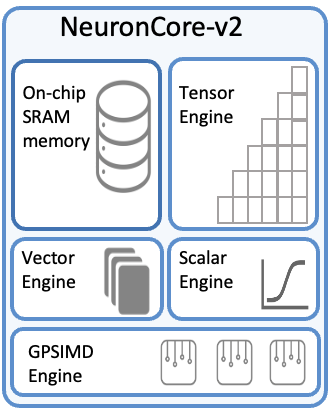
Just like in NeuronCore-v1, The ScalarEngine is optimized for scalar-computations, in which every element of the output is dependent on one element of the input. The ScalarEngine is highly parallelized, and delivers 2.9 TFLOPS of FP32 computations (3x speedup relative to NeuronCore-v1). The NeuronCore-v2 ScalarEngine can handle various data types, including cFP8, FP16, BF16, TF32, FP32, INT8, INT16, and INT32.
The VectorEngine is optimized for vector computations, in which every element of the output is dependent on multiple input elements. Examples include ‘axpy’ operations (Z=aX+Y), Layer Normalization, Pooling operations, and many more. The VectorEngine is also highly parallelized, and delivers 2.3 TFLOPS of FP32 computations (10x speedup vs. NeuronCore-v1). The NeuronCore-v2 VectorEngine can handle various data-types, including cFP8, FP16, BF16, TF32, FP32, INT8, INT16 and INT32.
The TensorEngine is based on a power-optimized systolic-array, which is highly optimized for tensor computations (e.g., GEMM, CONV, Transpose), and supports mixed-precision computations (cFP8 / FP16 / BF16 / TF32 / FP32 / INT8 inputs, FP32 / INT32 outputs). Each NeuronCore-v2 TensorEngine delivers over 90 TFLOPS of FP16/BF16 tensor computations (6x speedup from NeuronCore-v1).
NeuronCore-v2 also introduces a new engine called the GPSIMD-Engine, which consists of eight fully-programmable 512-bit wide vector processors, which can execute general purpose C-code and access the embedded on-chip SRAM memory. With these cores, customers can implement custom operators and execute them directly on the NeuronCores.
NeuronCore-v2 also adds support for control flow, dynamic shapes, and programmable rounding mode (RNE & Stochastic-rounding).
This document is relevant for: Inf2, Trn1