
This document is relevant for: Trn2, Trn3
About the NKI Compiler#
This topic covers the NKI Compiler and how it interacts with the Neuron Graph Compiler to produce a complete model. The NKI Compiler is responsible for compiling NKI kernels.
Overview#
The NKI language allows kernel writers to have direct, fine grained control over Neuron devices. Through low level APIs that reflect the Neuron instruction set architecture (ISA), NKI empowers developers to take direct control over critical performance optimizations during kernel development. This approach requires a dedicated NKI Compiler, separate from the existing Neuron Graph Compiler, which compiles kernel code while preserving the developer’s optimization choices. To seamlessly integrate NKI into model architectures defined in machine learning frameworks like JAX and PyTorch, the NKI Compiler also works in conjunction with the Neuron Graph compiler.
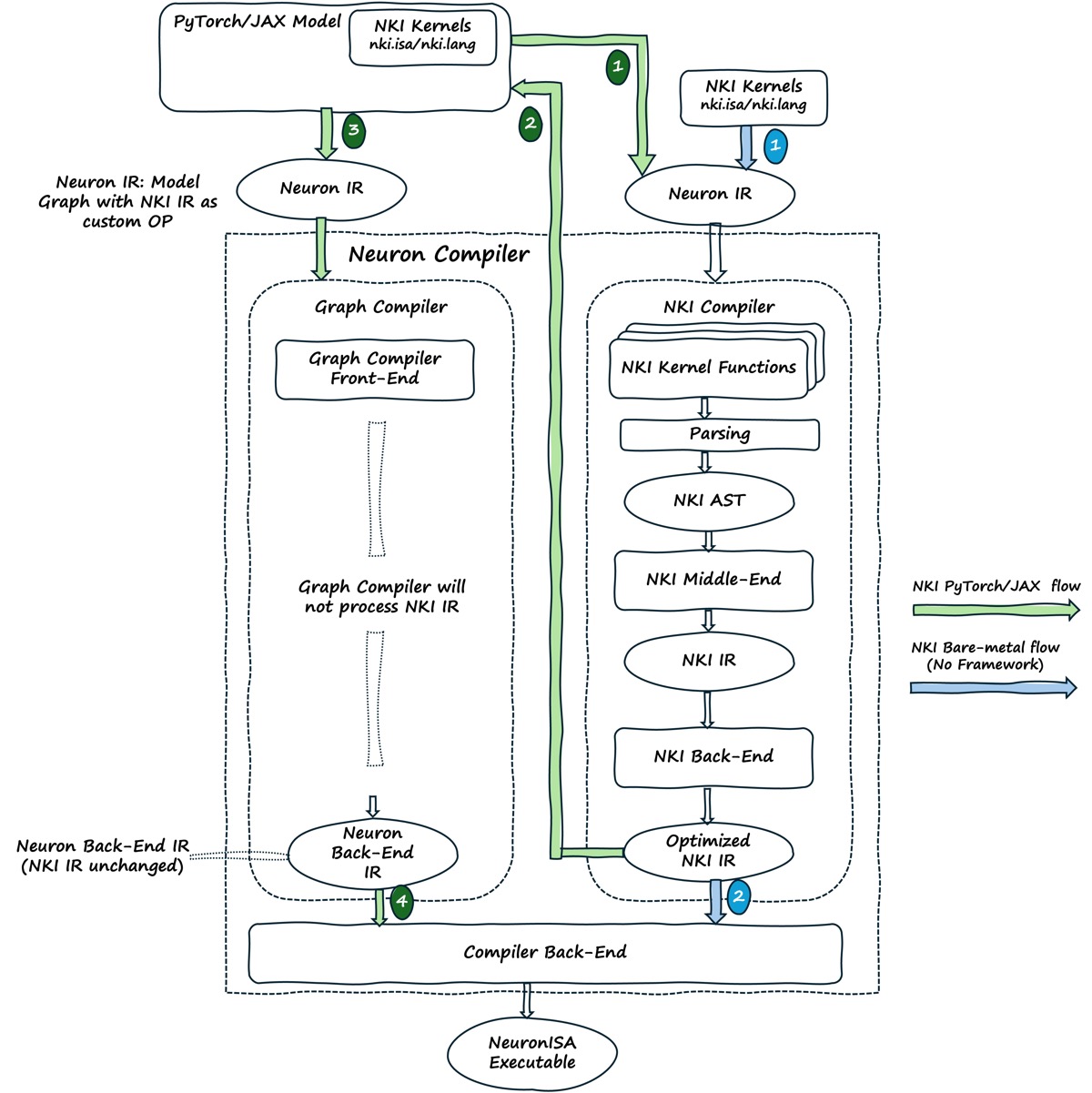
The diagram below shows the detailed compilation flow inside the Neuron compilers and how they work together to build the overall binary that is executable on Neuron hardware. The NKI Compiler first parses the kernel code into an AST representation for semantic analysis. It then performs a small number of middle end and back end transformations on the AST, optimizing resource allocations and instruction scheduling, producing optimized NKI IR that gets integrated back into the overall model.
Important
While the NKI meta-programming language looks and feels like Python, it is not actually Python code. When the Python interpreter encounters a top level function decorated with @nki.jit, it invokes the NKI Compiler to handle compilation of that function.
# this is a Python function that calls 'kernel', which is a NKI kernel
def a_function(x,y,z):
kernel(x, y, z)
# this is a NKI kernel that will be compiled by the NKI Compiler and
# integrated back into the overall model by the Neuron Graph compiler
@nki.jit
def kernel(x,y,z):
# this is kernel code
Using Python features within NKI kernels that are not supported will result in useful errors from the NKI Compiler indicating that the feature is not a valid NKI feature. Neuron has intentionally constrained the NKI meta-programming language to be as minimal as possible while serving the needs of building high performance kernels for today’s popular models and will continue to grow and evolve the language over time.
NKI Compiler Open Source#
Neuron is planning to release the source code for the NKI Compiler to increase awareness and transparency, to enable easier development of tools, and to invite participation and collaboration as we evolve the NKI language. Developers will be able to download the compiler sources, modify them, build the compiler, and use their locally built compiler in their overall model compilation flow.
To do this, developers will be able to download our sources from our public git repository in the aws-neuron GitHub organization (aws-neuron/).
The repo contains all the sources for the entire NKI Compiler, as well as build instructions on how to produce a standalone nki.whl. Once built, developers can install their locally built wheel: pip install nki.whl. This will replace the default NKI Compiler that is installed with the Neuron SDK package. The local wheel will then be registered to handle subsequent @nki.jit decorators and will be picked up and integrated with the rest of the Neuron Graph compiler flow.
Note that upon installing a locally-built wheel, developers must reinstall the Neuron SDK in order to revert their changes to the official version of the NKI Compiler. Also, the officially built compiler will have an officially tagged version whereas locally built versions will not. Any bug and error reports will contain the version of the compiler used.
How the NKI Compiler Works with the Graph Compiler#
For each kernel function, Neuron runs the NKI Compiler to produce an artifact for that kernel function. This is similar to compiling a single file with a traditional compiler, such as a C++ compiler.
All of the kernel artifacts are managed by the Neuron SDK. Programmers do not
need to manage these files themselves. Similar to prior versions of NKI,
programmers mark kernel functions with nki.jit—the NKI Compiler will be
invoked automatically when this decorator is encountered during compilation.
The Neuron Graph Compiler (or just the Neuron Compiler) handles the rest of the model, which we refer to as “the compute graph”. The framework, such as PyTorch or Jax, orchestrates the process of building a compute graph from the model definition. When the model includes a call to a NKI kernel function, the NKI Compiler will insert a reference to the compiled artifact into the graph. The Graph Compiler recognizes these references and assembles the final result that can be run on the Trainium Hardware.
Integration#
As described above, both the NKI Compiler and the Neuron Compiler are used to construct the final artifact that can be run on Trainium hardware. The NKI Compiler compiles each NKI kernel function in turn, and the Neuron Compiler compiles the whole model and inserts the NKI kernels based on the references generated by the NKI Compiler.
This insertion of NKI kernels into the graph is done very late in the compilation process. This is different from prior versions of NKI that integrated NKI kernels earlier in the compile process. Insertion later in the process allows the NKI Compiler to provide custom behavior for NKI and give users a more predictable and performant result.
Further reading#
This document is relevant for: Trn2, Trn3