
This document is relevant for: Inf2, Trn1
Track Training Progress in TensorBoard using PyTorch Neuron#
This tutorial explains how to track training progress in TensorBoard while running a multi-layer perceptron MNIST model on Trainium using PyTorch Neuron.
Multi-layer perceptron MNIST model#
This tutorial is based on the MNIST example for PyTorch Neuron on Trainium. For the full tutorial, please see Multi-Layer Perceptron Training Tutorial.
Output TensorBoard logs#
To generate TensorBoard logs, we first modify the training script to use the SummaryWriter:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('./output')
In the training loop, we can then use the add_scalar API to log the loss per step.
writer.add_scalar("step loss", loss, idx)
At the end of the script, add writer.flush() to ensure all logs are written.
Save the following code as train_tb.py and run it as python3 train_tb.py on a Trn1 instance.
The generated logs can be found in the ./output directory that was passed to SummaryWriter.
import os
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.datasets import mnist
from torch.optim import SGD
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
# XLA imports
import torch_xla.core.xla_model as xm
from torch.utils.tensorboard import SummaryWriter
# Declare 3-layer MLP for MNIST dataset
class MLP(nn.Module):
def __init__(self, input_size = 28 * 28, output_size = 10, layers = [120, 84]):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, layers[0])
self.fc2 = nn.Linear(layers[0], layers[1])
self.fc3 = nn.Linear(layers[1], output_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1)
# Load MNIST train dataset
train_dataset = mnist.MNIST(root='./MNIST_DATA_train', \
train=True, download=True, transform=ToTensor())
def main():
# Prepare data loader
train_loader = DataLoader(train_dataset, batch_size=32)
# Fix the random number generator seeds for reproducibility
torch.manual_seed(0)
# XLA: Specify XLA device (defaults to a NeuronCore on Trn1 instance)
device = 'xla'
# Move model to device and declare optimizer and loss function
model = MLP().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
loss_fn = torch.nn.NLLLoss()
# Use SummaryWriter to generate logs for TensorBoard
writer = SummaryWriter('./output')
# Run the training loop
print('----------Training ---------------')
model.train()
start = time.time()
for idx, (train_x, train_label) in enumerate(train_loader):
optimizer.zero_grad()
train_x = train_x.view(train_x.size(0), -1)
train_x = train_x.to(device)
train_label = train_label.to(device)
output = model(train_x)
loss = loss_fn(output, train_label)
writer.add_scalar("step loss", loss, idx) # add the step loss to the TensorBoard logs
loss.backward()
optimizer.step()
xm.mark_step() # XLA: collect ops and run them in XLA runtime
if idx < 2: # skip warmup iterations
start = time.time()
# Compute statistics
interval = idx - 2 # skip warmup iterations
throughput = interval / (time.time() - start)
print("Train throughput (iter/sec): {}".format(throughput))
print("Final loss is {:0.4f}".format(loss.detach().to('cpu')))
# Ensure TensorBoard logs are all written
writer.flush()
# Save checkpoint for evaluation
os.makedirs("checkpoints", exist_ok=True)
checkpoint = {'state_dict': model.state_dict()}
# XLA: use xm.save instead of torch.save to ensure states are moved back to cpu
# This can prevent "XRT memory handle not found" at end of test.py execution
xm.save(checkpoint,'checkpoints/checkpoint.pt')
print('----------End Training ---------------')
if __name__ == '__main__':
main()
View loss in TensorBoard#
In order to view your training metrics, install TensorBoard in your Python environment:
pip install tensorboard
Then, launch TensorBoard with the ./output directory
tensorboard --logdir ./output
Once running, open a new SSH connection to the instance and port-forward TCP port 6006 (ex: -L 6006:127.0.0.1:6006). Once the tunnel is established, TensorBoard can then be accessed via web browser at the following URL: http://localhost:6006. Please note that you will not be able to access TensorBoard if you disconnect your port-forwarding SSH session to the Trainium instance.
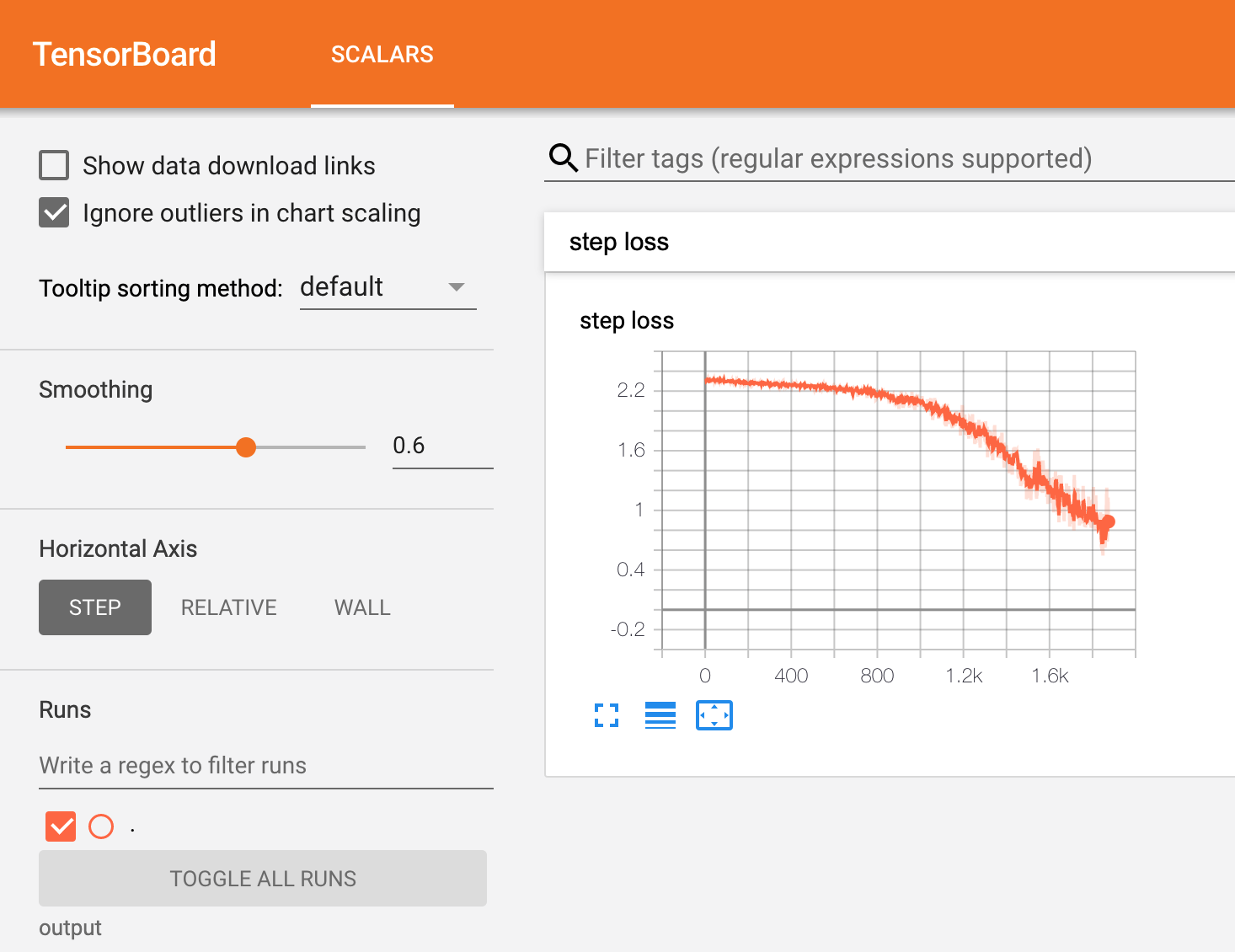
In TensorBoard, you can now see the loss per step plotted.
When capturing loss for multiple runs, you can plot them together on the same graph to compare runs.
Be sure to change the output directory for different runs, for example ./output/run1 for the first, ./output/run2 for the second, etc.
This document is relevant for: Inf2, Trn1