
This document is relevant for: Inf2
Amazon EC2 Inf2 Architecture#
On this page we provide an architectural overview of the Amazon EC2 Inf2 instances and the corresponding Inferentia2 NeuronChips that power them (Inferentia2 chips from here on).
Inf2 Architecture#
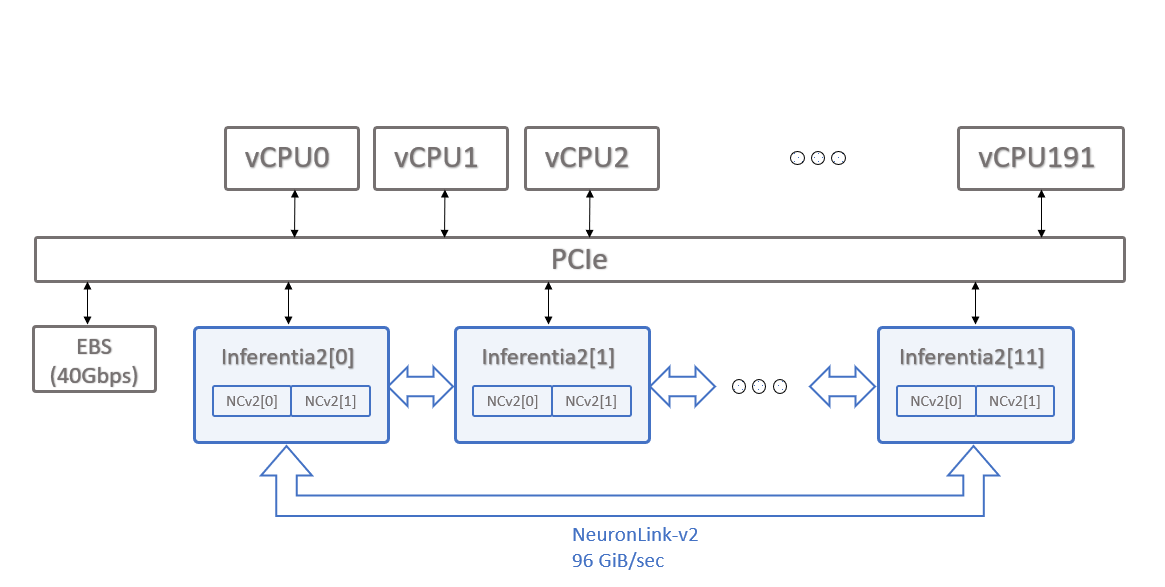
The EC2 Inf2 instance is powered by up to 12 Inferentia2 chips, and allows customers to choose between four instance sizes:
Instance size |
# of Inferentia2 chips |
vCPUs |
Host Memory (GiB) |
FP8/FP16/BF16/TF32 TFLOPS |
FP32 TFLOPS |
Device Memory (GiB) |
Instance Memory Bandwidth (GiB/sec) |
NeuronLink-v2 chip-to-chip (GiB/sec/chip) |
|---|---|---|---|---|---|---|---|---|
Inf2.xlarge |
1 |
4 |
16 |
190 |
47.5 |
32 |
820 |
N/A |
Inf2.8xlarge |
1 |
32 |
128 |
190 |
47.5 |
32 |
820 |
N/A |
Inf2.24xlarge |
6 |
96 |
384 |
1140 |
285 |
192 |
4920 |
192 |
Inf2.48xlarge |
12 |
192 |
768 |
2280 |
570 |
384 |
9840 |
192 |
Inf2 offers a low-latency, high-bandwidth chip-to-chip interconnect called NeuronLink-v2, which enables high-performance collective communication operations (e.g., AllReduce and AllGather).
This allows sharding large models across Inferentia2 chips (e.g., via Tensor Parallelism), thus optimizing latency and throughput. This capability is especially useful when deploying Large Generative Models.
This document is relevant for: Inf2