
This document is relevant for: Trn1, Trn2, Trn3
What is Neuron Collective Communication?#
This topic covers Neuron Collective Communication and how it applies to developing with the AWS Neuron SDK. Collectives are distributed communication primitives that enable ranks in a distributed workload to exchange data using simple, well-defined semantics. In Neuron, each rank can be represented by a physical or logical Neuron Core.
Overview#
Modern neural networks with billions to trillions of parameters exceed single-machine computational capacity, making distributed machine learning essential for training and deployment. Collectives are a set of distributed computing primitives with simple semantics, originally developed in HPC.
Collective communication coordinates data exchange among multiple processes in distributed systems. Unlike point-to-point communication, collective operations involve groups performing tasks like gradient aggregation, parameter sharing, and computation synchronization.
Applies to#
This concept is applicable to:
Distributed Training: Collective communication aggregates and synchronizes gradients across workers to maintain model consistency. In this scenario, collective operations enable workers to compute gradient sums across all nodes, ensuring uniform parameter updates.
Distributed Inference: During inference, collective communication distributes requests across multiple accelerators in serving nodes, optimizing resource utilization and maintaining low latency under high loads.
In distributed training, workers compute gradients on different data batches simultaneously. Collective communication aggregates and synchronizes gradients across workers to maintain model consistency. Also, during inference, collective communication distributes requests across multiple accelerators in serving nodes, optimizing resource utilization and maintaining low latency under high loads.
From a developer perspective, the training/inference code will have high-level invocations to collective functions like (PyTorch) all_gather, all_reduce, reduce_scatter, all_to_all, permute, and others. See below for a visual representation of some key collective operations:
Collective Operations#
AllGather Operation#
In the AllGather operation, each rank shares its tensor and receives the aggregated tensors from all ranks, ordered by rank index.
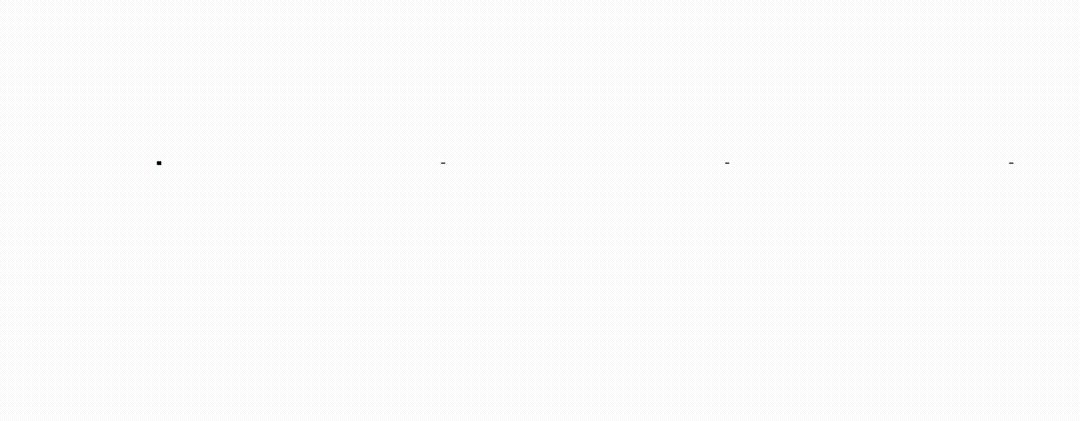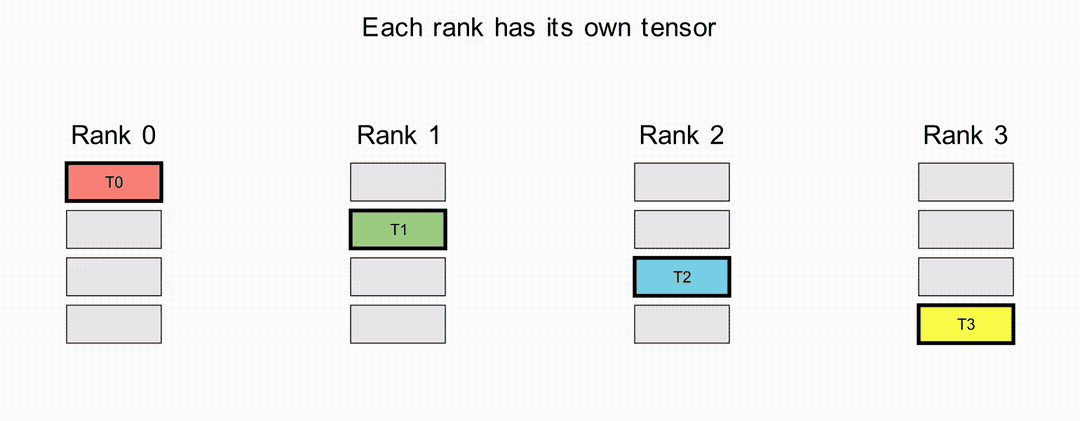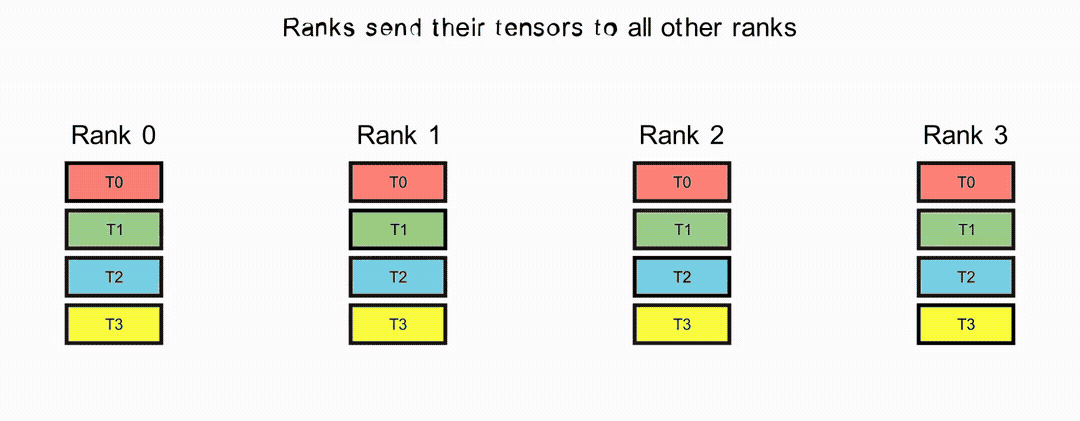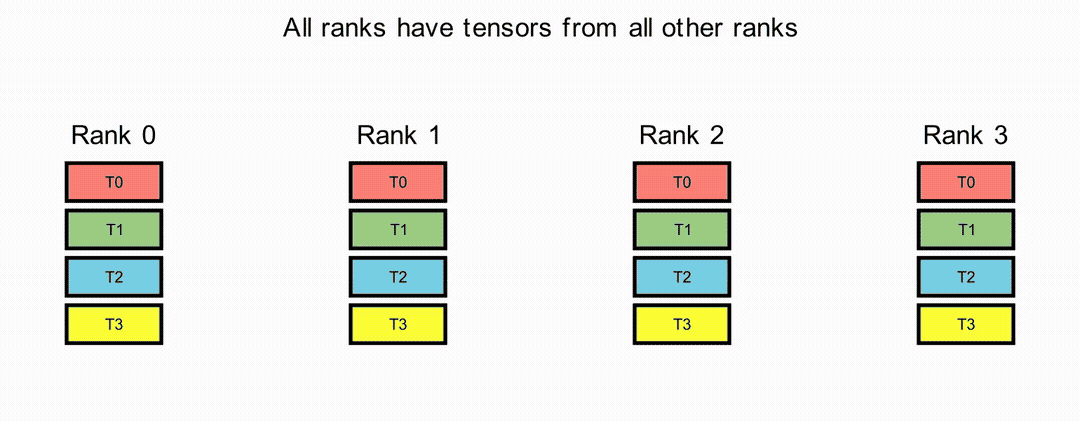
ReduceScatter Operation#
The ReduceScatter operation performs reductions on input data (for example, sum, min, max) across ranks, with each rank receiving an equal-sized block/piece of the result based on its rank index.

AllReduce Operation#
The AllReduce operation performs reductions on data (e.g., sum, max, min) across ranks and stores the result in the output buffer of every rank.

All-to-All Operation#
In AlltoAll, each rank sends different data to and receives different data from every other rank, resembling a distributed transpose.

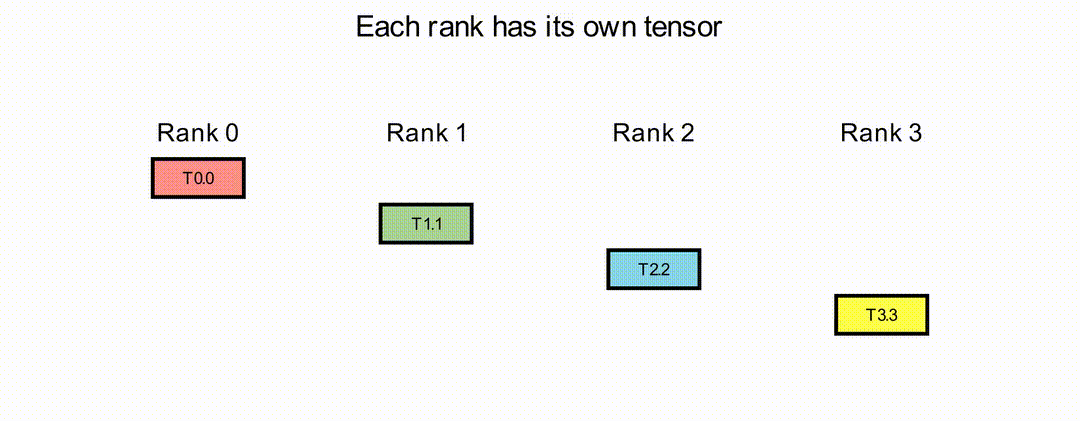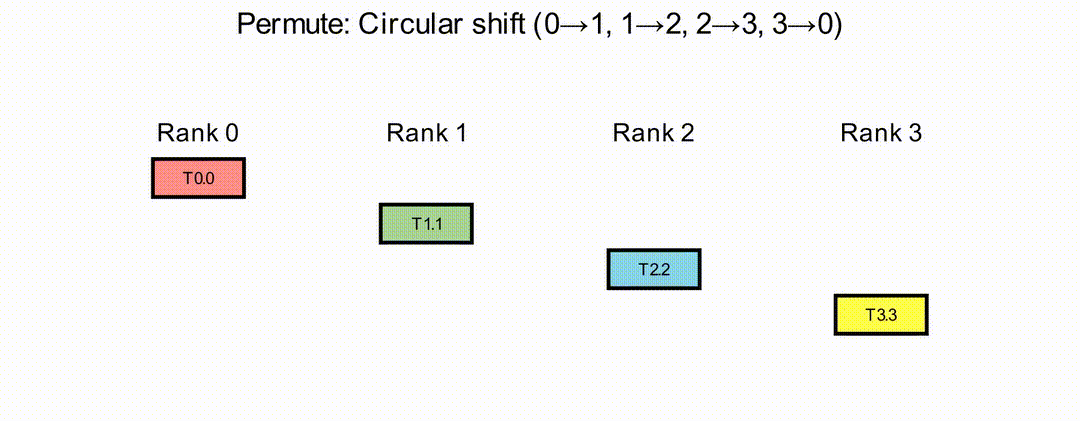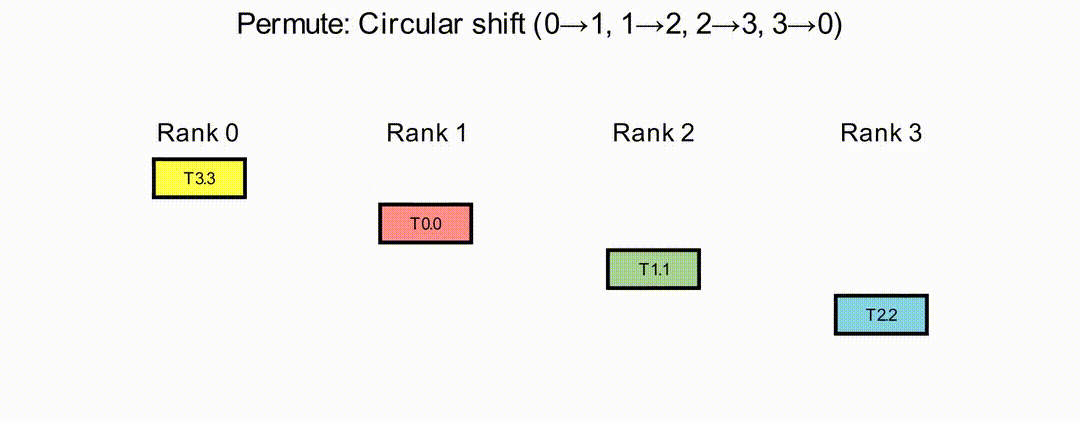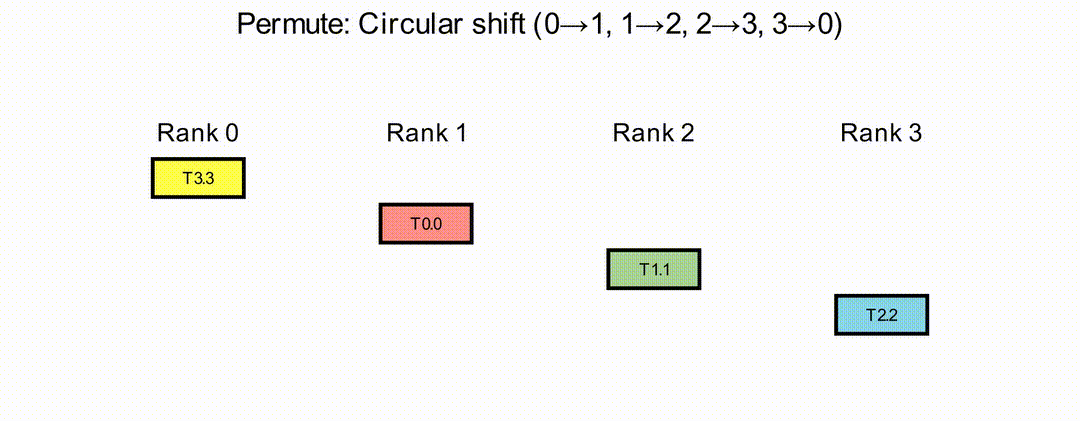
Permute Operation#
In the Permute operation, each rank sends its data to a designated destination rank and receives data from a designated source rank, according to a set of source-target pairs. The source-target pairs must form a valid ring topology with direct physical connectivity between adjacent ranks. Only ranks included in the source-target pairs participate in the collective execution; other ranks remain inactive during the operation. Currently, only circular permute patterns are supported.
Communication Scope#
Collective communication operations can be further categorized based on their scope within the distributed system topology. Understanding this distinction is crucial for optimizing performance and minimizing communication overhead in large-scale distributed training and inference. Collectives can be grouped into two main categories:
Intra-node Collectives#
Intra-node collectives operate within a single node or a group of nodes where all corresponding Neuron Chips are physically interconnected using NeuronLinks. These operations typically leverage high-bandwidth, low-latency chip-to-chip connections, high-speed PCIe links and NeuronLink interconnections. Since data remains within the local memory (in one or more interconnected nodes) hierarchy, intra-node collectives generally offer superior bandwidth and lower latency compared to inter-node communication. However, depending on the size of the model, multiple nodes are required for the job.
For more details, see Intra-node Collective Communications with AWS Neuron.
Inter-node Collectives#
Inter-node collectives coordinate communication across multiple physical nodes in a distributed cluster, requiring data to traverse network infrastructure via EFA (Elastic Fabric Adapter) connections. While inter-node communication typically has higher latency and lower bandwidth than intra-node alternatives, it enables scaling beyond the computational limits of a single machine. Efficient inter-node collective implementations often employ hierarchical communication patterns, where intra-node operations are performed first, followed by inter-node coordination among designated processes.
Modern distributed training frameworks automatically optimize collective operations by combining intra-node and inter-node communication strategies. For example, in a Trn2 cluster, an all-reduce operation across 256 accelerators distributed across 4 nodes might first perform local reductions within each 64-accelerator node, then execute inter-node communication between the 4 nodes, and finally broadcast results back within each node.
For more details, see Inter-node Collective Communications with AWS Neuron.
System Connectivity#
Each Trainium 2 server (trn2.48xlarge or trn2u.48xlarge) consists of 16 Trainium2 chips, each connected to a 200Gbps EFA (Elastic Fabric Adapter) network interface, for an aggregated 3.2Tbps device-RDMA connectivity. Each Trainium2 chip consists of eight physical NeuronCores. These physical cores can also be configured as Logical Cores or LNC (Logical Neuron Core). By default, each two NeuronCores are exposed as one (Logical) rank (LNC=2), but under LNC=1, they’re exposed as two. In LNC=2, each chip is exposed as 4 ranks for a total of 64 ranks per server, and each rank gets 3.2 Tbps / 64 = 50Gbps. In the case of LNC=1, each chip is exposed as 8 ranks, and each rank gets 50 Gbps / 2 = 25Gbps.
Each NeuronCore has dedicated components to actually realize collective operations called CC Cores. The collectives communication cores (CC cores) are dedicated synchronization processors responsible for the orchestration of collective communications. The CC cores control when and how data movement engines transfer data, ensuring each step of the collective algorithm executes in the correct order.
Latency-wise, Trn2.48xl instances are backed by the AWS 10p10u network. When measured with the RDMA core performance test ib_write_lat, a minimal packet takes 15us (latency) to go from an HBM in one server to an HBM of another.
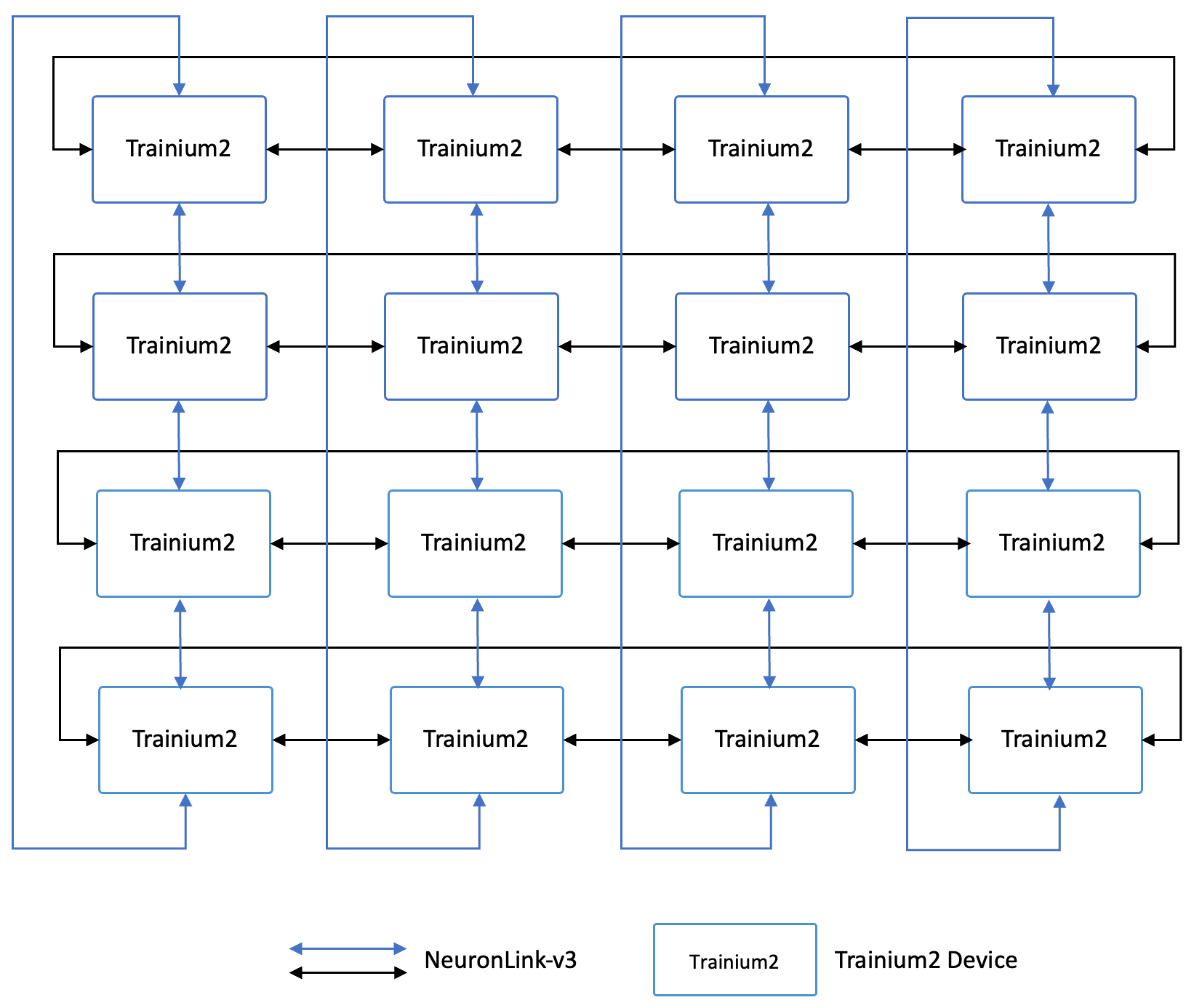
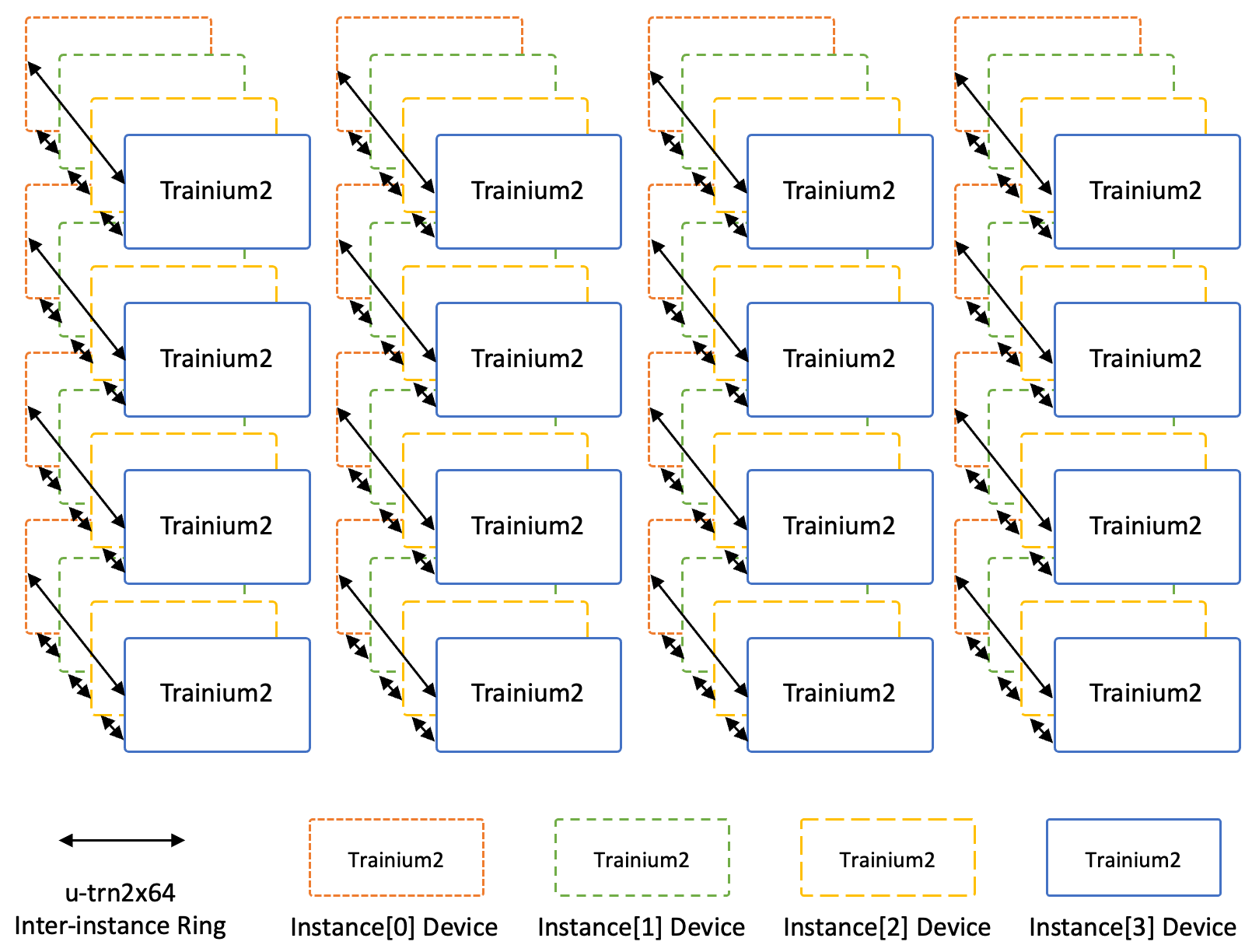
Each Trn2 server consists of 16 Trainium2 chips connected in a 2D Torus — each chip is connected to 4 neighbors with a NeuronLink. For an UltraServer configuration, we extend this to a 3D Torus, with each chip adding connections on the Z dimensions to 2 neighbors with a bidirectional NeuronLink between each pair.
Read more#
For more details about how collectives are implemented in Neuron, see the following pages:
This document is relevant for: Trn1, Trn2, Trn3