
This document is relevant for: Trn1, Trn2
Overview#
NxD Training#
The NeuronX Distributed Training (NxD Training) library is a collection of open-source tools and libraries designed to empower customers to train PyTorch models on AWS Trainium instances. It combines both ease-of-use and access to features built on top of NxD Core library. Except for a few Trainium specific features, NxD Training is compatible with training platforms like NVIDIA’s NeMo.
Specifically, NxD Training offers the following features and productivity flows:
Training Workflows: Developers benefit from turnkey support for multiple workflows such as model Pre-training, Supervised Finetuning (SFT), and Parameter Efficient Finetuning (PEFT) using Low Rank Adapters (LoRA) [1]. For these workflows, precision types supported include (a) FP32 for both baseline and for master weights when using ZeRO-1, and (b) BF16 combined with stochastic rounding.
Distributed Strategies: Splitting training workload over multiple nodes shortens the job duration. This is made possible through distributed strategies that are the techniques used to shard large scale models across multiple Neuron Cores. NxD Training Distributed Strategies are implemented in the NxD Core library and include: Data Parallelism, Tensor-parallelism, Sequence-Parallelism, Pipeline-parallelism (including 1F1B pipeline schedule and interleaved pipeline schedule), and ZeRO-1.
Data Science Modules: The integration of datasets, dataloaders, tokenizers and other data wrangling tools makes it easy to prepare and use large-scale training data.
Data Engineering Modules: Integrated Experiment Manager allows for saving training outputs through checkpointing and evaluating results through enhanced logging. It comes with multiple options for optimally loading/saving checkpoints such as sharded checkpoints, last-K checkpoints, asynchronous checkpoints, auto-resume from checkpoints and storage in S3 buckets.
PyTorch Lightning: NxD Training is integrated with training frameworks like like PyTorch Lightning that help with organizing training code.
Models: Users can start on NxD Training with ready-to-use samples based on HuggingFace and Megatron-LM model formats. It has support for advanced LLM architecture blocks such as Grouped Query Attention layer.
SW Releases: NxD Training code is available on GitHub, both as pip wheel and source code.
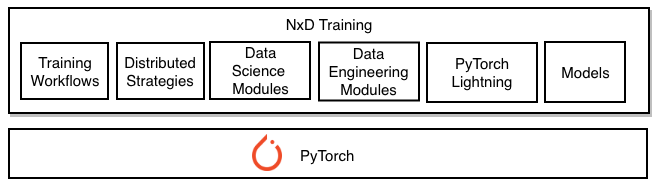
Fig. 1 NxD Training#
Using NxD Training#
ML developers often need access to training code at different levels of abstraction. As shown in figure, using NxD Training is possible using three interfaces:
High-level YAML configuration file used in conjunction with models in NxD Training’s model hub
PyTorch Lightning (PTL) APIs and Trainer in conjunction with NxD Core primitives
NxD Core foundational API, also referred to as NxD Core primitives
All three usage mechanisms employ the underlying NxD Core library either directly through programming interfaces or configuration files and developers can choose the method that meets their needs.
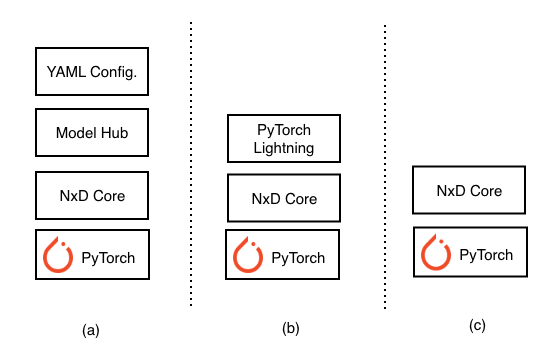
Fig. 2 Using NxD Training through (a) Configuration Files (b) PyTorch Lightning APIs, and (c) NxD Core primitives#
Configuration File#
NxD Training supports a top-level access for distributed training using YAML based configuration files. This option is available for models that are available in the model hub or custom ones enabled after following the steps listed in model integration guide inside NxD Training. With this usage model, only the configuration parameters inside the YAML file need to be set and no further code changes are necessary. This facilitates easy experimentation with various configuration settings and automating the workflow. Figure below shows the major settings available inside YAML configuration file and more details on how to exercise these options are in YAML Configuration Settings. Existing users of NeuronX NeMo Megatron (NNM) or NVIDIA NeMo can review NNM and NeMo migration guides, respectively, to map the configuration parameters to NxD Training.

Fig. 3 Top level settings for NxD Training through configuration file#
PyTorch Lightning APIs#
PyTorch Lightning is a library that abstracts out model training workflows and eliminates the boilerplate code to setup training loops. Through its inheritable classes for training loops, data and customizable callbacks for checkpointing and distributed strategies, developers can set training workflows in a standardized and compact manner.
As shown in user interfaces to NxD Training, Figure (b), overall training scripts can be built
using PyTorch Lightning and making use of NxD Core library.
This requires overriding the base classes of PyTorch Lightning such as LightningModule, DataModule;
configuring optimizer and LR scheduler;setting appropriate callbacks; and launching the Trainer.
For more details, refer to NxD Core’s PyTorch Lightning developer guide
and sample tutorial.
NxD Core Primitives#
NxD Core primitives are basic APIs that can be stitched together to build complete training workflows for AWS Trainium instances. Addtionally, these primitives are required for integrating a new custom model into NxD Training or using the model directly via NxD Core library.
NxD Core library has support for all the essential training features - model sharding, handling collective communications, memory reduction, checkpointing, optimizer setting and profiling. For example, tensor parallelism through NxD Core is achieved by converting the linear layers, common in attention modules of transformer-architecture based models, to parallel layers. For pipeline parallelism, NxD Core offers ability for both manual and automatic selection of pipeline cut points in the model graph. Additional options for sequence parallelism and activation recomputation help with memory reduction. For all these parallelism options, NxD Core library automatically ensures efficient management of all the required collective communications across Neuron Cores.
Exact details on how these capabilities can be exercised are described in NxD Core developer guide. For background information and description of NxD Core primitives, users are referred to NxD Core’s app notes, and API guide, respectively. Following these steps, once a new model is onboarded using NxD Core APIs, its training workflow can be streamlined using NxD Training’s experiment manager and data science/engineering modules.
This document is relevant for: Trn1, Trn2