
This document is relevant for: Inf2, Trn1, Trn2
Graph Partitioner on torch_neuronx#
Introduction#
This guide introduces the graph partitioner for torch-neuronx. The following sections explain the purpose of the graph partitioner, how it works, and go over a few examples.
The Purpose of the Graph Partitioner#
While neuronx-cc is very sophisticated and can compile most operators,
there are some operator configurations that are not supported by the compiler.
Usually in a model that contains unsupported operators, these are only a few
operators while the supported parts of the model can benefit from the acceleration
benefits that Neuron offers. With this in mind, we developed a graph partitioner
that will partition out unsupported operators to be executed on CPU, while
compiling and executing the supported operators on Neuron.
How it Works#
Determining Unsupported Operators#
Operator support is determined by the neuronx-cc compiler frontend. This is done
because this gives us more flexibility than a static list. This is evident
in cases where a specific operator configuration is supported but another
configuration is not supported. For example, we support the square root operator,
but do not support it with a C64 data type for example.
To check operator support, we use the torch_neuronx.analyze() API, which
queries the compiler for device placement: Neuron or CPU, which gives the graph
partitioner a base graph to start partitioning.
The below image shows the flow of the graph partitioner:
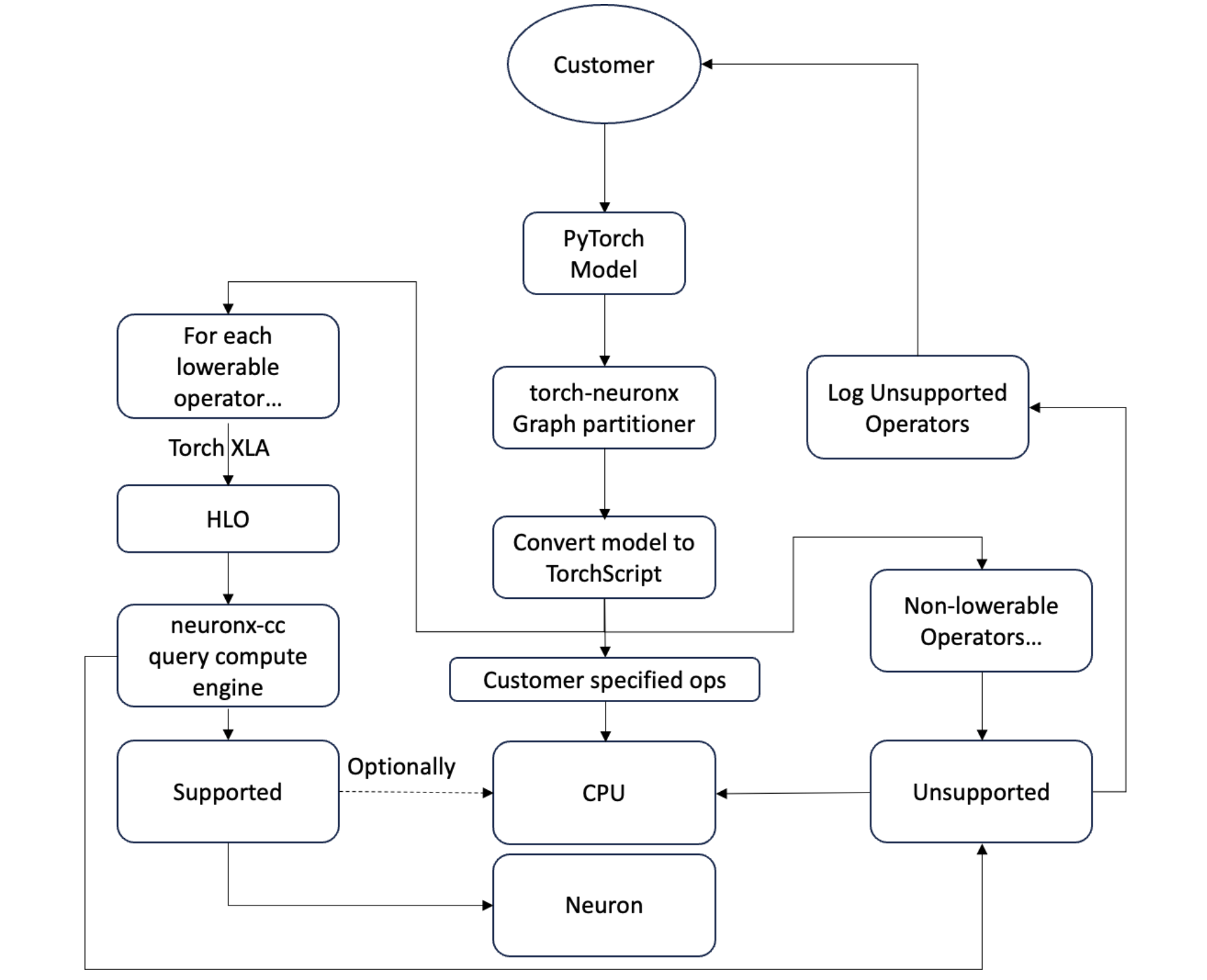
Customizability#
The graph partitioner has a wide range of customizability for a variety of situations. The customization options include:
Minimum Operator Support: Only partition the model if a minimum percentage of operators are supported.
Minimum Subgraph Size: The minimum number of operators in any given subgraph. This can be useful if having compute chokepoints with single operator subgraphs is not desired.
Maximum Subgraph Count: The maximum number of subgraphs. Too many subgraphs can fragment the computation graph causing performance degredation.
Ops to Partition: Additional operators to partition to CPU beyond the unsupported operators. This can be useful to suggest to the graph partitioner to partition to create a more balanced graph.
Furthermore, compiler flags/args can be passed into all Neuron subgraphs through the graph partitioner.
For the API Reference, visit torch_neuronx.trace() and torch_neuronx.PartitionerConfig
Note
Dynamic batching has a case-by-case support with partitioned models, because it is highly dependent on how the final partition scheme looks like.
Examples#
The following sections provide example usages of the graph partitioner.
Default Usage#
The below model is a simple MLP model with sorted log softmax output.
The sort operator, torch.sort() or aten::sort, is not supported
by neuronx-cc at this time, so the graph partitioner will partition
out the sort operator to CPU.
import torch
import torch_neuronx
import torch.nn as nn
import logging
# adjust logger level to see what the partitioner is doing
logger = logging.getLogger("Neuron")
class MLP(nn.Module):
def __init__(
self, input_size=28 * 28, output_size=10, layers=[4096, 2048]
):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, layers[0])
self.fc2 = nn.Linear(layers[0], layers[1])
self.fc3 = nn.Linear(layers[1], output_size)
self.relu = nn.ReLU()
def forward(self, x):
f1 = self.fc1(x)
r1 = self.relu(f1)
f2 = self.fc2(r1)
r2 = self.relu(f2)
f3 = self.fc3(r2)
out = torch.log_softmax(f3, dim=1)
sort_out,_ = torch.sort(out)
return sort_out
n = MLP()
n.eval()
inputs = torch.rand(32,784)
# Configure the graph partitioner with the default values
partitioner_config = torch_neuronx.PartitionerConfig()
# Trace a neural network with graph partitioner enabled
neuron_net = torch_neuronx.trace(n, inputs, partitioner_config=partitioner_config)
# Run inference on the partitioned model
output = neuron_net(inputs)
Specifying requirements#
This example is very similar to the previous example, but has two differences. The unsupported sort operator is sandwiched between the ReLU activation function after the first linear layer and the second linear layer. The second difference is that we are specifying a max subgraph count of 2.
import torch
import torch_neuronx
import torch.nn as nn
import logging
# adjust logger level to see what the partitioner is doing
logger = logging.getLogger("Neuron")
class MLP(nn.Module):
def __init__(
self, input_size=28 * 28, output_size=10, layers=[4096, 2048]
):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, layers[0])
self.fc2 = nn.Linear(layers[0], layers[1])
self.fc3 = nn.Linear(layers[1], output_size)
self.relu = nn.ReLU()
def forward(self, x):
f1 = self.fc1(x)
r1 = self.relu(f1)
sort_r1,_ = torch.sort(r1)
f2 = self.fc2(sort_r1)
r2 = self.relu(f2)
f3 = self.fc3(r2)
out = torch.log_softmax(f3, dim=1)
return out
n = MLP()
n.eval()
inputs = torch.rand(32,784)
# Configure the graph partitioner with the default values
partitioner_config = torch_neuronx.PartitionerConfig(max_subgraph_count=2)
# This trace will fail since the min_subgraph_size requirement can't be satisfied by the graph partitioner
neuron_net = torch_neuronx.trace(n, inputs, partitioner_config=partitioner_config)
Output:
ValueError: The partitioner has found 3 subgraphs which exceeds the specified max subgraph count of 2.
This example fails because the sort operator placement generates 3 subgraphs, which is more than 2.
Specifying additional operators to partition#
This example shows a situation where we want to partition out the log_softmax operator despite it being supported. We also specify an 80% support percentage threshold.
import torch
import torch_neuronx
import torch.nn as nn
import logging
# adjust logger level to see what the partitioner is doing
logger = logging.getLogger("Neuron")
logger.setLevel(logging.INFO)
class MLP(nn.Module):
def __init__(
self, input_size=28 * 28, output_size=10, layers=[4096, 2048]
):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, layers[0])
self.fc2 = nn.Linear(layers[0], layers[1])
self.fc3 = nn.Linear(layers[1], output_size)
self.relu = nn.ReLU()
def forward(self, x):
f1 = self.fc1(x)
r1 = self.relu(f1)
f2 = self.fc2(r1)
r2 = self.relu(f2)
f3 = self.fc3(r2)
out = torch.log_softmax(f3, dim=1)
sort_out,_ = torch.sort(out)
return sort_out
n = MLP()
n.eval()
inputs = torch.rand(32,784)
# Configure the graph partitioner with the default values
partitioner_config = torch_neuronx.PartitionerConfig(min_operator_percentage_threshold=0.8,ops_to_partition=set(["aten::log_softmax"]))
# This trace succeeds
neuron_net = torch_neuronx.trace(n, inputs, partitioner_config=partitioner_config)
Key Output logs:
...
Neuron: The following operations are currently supported:
Neuron: aten::linear
Neuron: aten::relu
Neuron: aten::log_softmax
Neuron: The following operations are currently not supported:
Neuron: aten::sort, unsup.py(28): <stack_trace>
...
Neuron: 85.71% of arithmetic operations (6 of 7) are supported
Neuron: Num Partitions: 2
Neuron: Creating Partition #1 for device: Device.NEURON
Neuron: The following operators will be included in this partition:
Neuron: prim::GetAttr:9
Neuron: aten::linear:3
Neuron: aten::relu:2
...
Neuron: Creating Partition #2 for device: Device.CPU
Neuron: The following operators will be included in this partition:
Neuron: prim::Constant:4
Neuron: aten::sort:1
Neuron: aten::log_softmax:1
Notice that we still report that aten::log_softmax is still supported, but also
report that aten::log_softmax is in Partition #2 which is for Device.CPU.
This document is relevant for: Inf2, Trn1, Trn2