
This document is relevant for: Trn2, Trn3
Native PyTorch for AWS Trainium#
Overview#
TorchNeuron is an open-source PyTorch backend that provides native PyTorch framework integration for AWS Trainium. TorchNeuron provides support for eager mode, torch.compile, and standard PyTorch native distributed APIs.
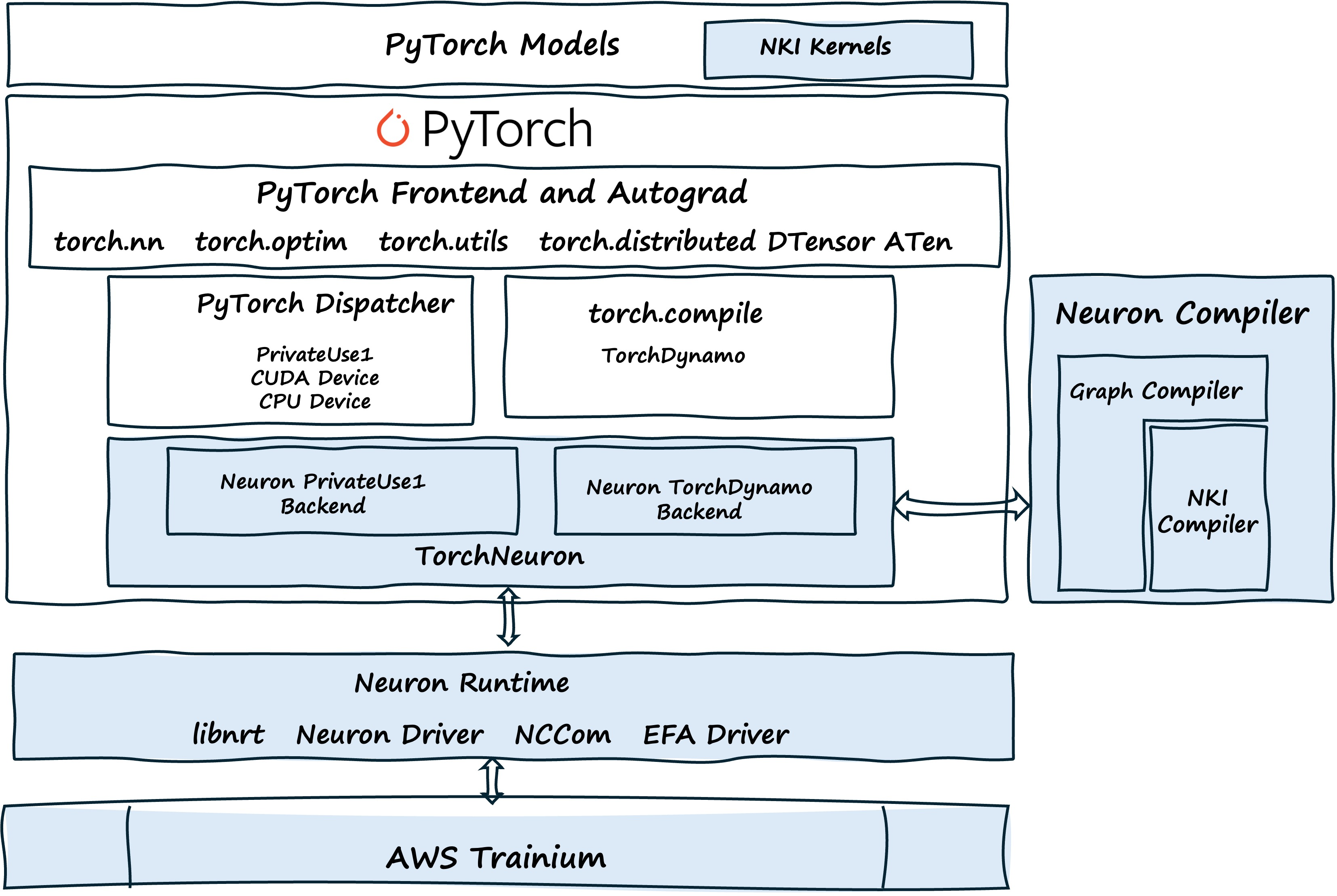
TorchNeuron#
Important
TorchNeuron is currently only available as part of a closed Beta program. If you would like to participate, contact your AWS Neuron support representative.
TorchNeuron is an open-source PyTorch extension that provides new native backend integration for AWS Trainium. The implementation includes support for eager mode for rapid iteration and experimentation, torch.compile for just-in-time compilation, and standard distributed processing APIs.
TorchNeuron enables ecosystem compatibility and supports custom kernel development through the Neuron Kernel Interface (NKI) for performance optimization and research applications.
PyTorch Eager Mode#
In eager mode, operations are dispatched and execute immediately upon invocation. PyTorch’s dispatcher routes tensor operations to the Neuron backend, which provides optimized implementations of ATen operators (core tensor operations) and distributed communication operators. These primitives execute directly on AWS Trainium hardware.
Adaptive Eager Execution#
TorchNeuron implements Adaptive Eager Execution to improve performance while maintaining functional accuracy and debuggability.
Adaptive Eager Execution applies optimizations such as operator fusion while guaranteeing identical stream order semantics and numerical accuracy.
torch.compile Support#
TorchNeuron supports torch.compile, enabling developers to JIT-compile some or all of their PyTorch code to improve performance on AWS Trainium.
TorchNeuron implements a custom backend for TorchDynamo that receives the forward and backward FX graphs and transforms them into optimized AWS Trainium instructions.
The TorchNeuron backend fully supports the caching mechanism provided by TorchDynamo.
Compilation Process#
When torch.compile is applied to a model on AWS Trainium:
TorchDynamocaptures Python bytecode and extracts PyTorch operations into an FX Graph during the forward pass.AOT Autogradgenerates forward and backward graphs.The Neuron Backend receives both FX graphs and lowers them to Neuron IR.
The Neuron Compiler applies hardware-specific optimizations and generates Trainium instructions for execution on the hardware.
Distributed Inference and Training Support#
TorchNeuron offers support for PyTorch distributed APIs, such as those included in the torch.distributed module, to support collective communications across sharded models, such as torch.distributed.all_reduce()).
Higher-level distributed training tools and techniques such as FSDP (Fully Sharded Data Parallel) and DTensor (Distributed Tensor) are implemented using these torch.distributed primitives to provide model parallelism and data parallelism strategies.
The Trainium backend supports the following torch.distributed APIs and techniques:
Fully Sharded Data Parallel (FSDP)
Distributed Tensor (DTensor)
Distributed Data Parallel (DDP)
Tensor Parallelism (TP)
Support for additional parallelism strategies such as Pipeline Parallelism (PP) will be available soon.
Neuron Kernel Interface (NKI) Integration#
TorchNeuron integrates with the Neuron Kernel Interface (NKI), enabling the development, optimization, and execution of custom operators.
NKI provides fine-grained control beyond adaptive eager execution and torch.compile. Developers can call performance-critical NKI kernels within training code to replace sequences of standard PyTorch operations. NKI kernels function in both eager and torch.compile modes, supporting:
Immediate execution and debugging capabilities in eager mode for rapid iteration
Graph-level optimizations with
torch.compilefor production deployment
NKI kernels integrate with native PyTorch code through the @nki.jit decorator and @nki_op for custom op registration.
Training models that include NKI kernels requires a backward version of the custom op, implemented using the register_autograd() function.
FAQs#
Getting Started FAQ#
Q: What is TorchNeuron?
TorchNeuron is an open-source native PyTorch backend for AWS Trainium that integrates through PyTorch’s standard PrivateUse1 device backend mechanism. TorchNeuron supports both eager mode execution and torch.compile. TorchNeuron is open source and initially available on GitHub at aws-neuron/torch-neuronx.
Q: What changes are needed to run my PyTorch code on Trainium?
Running your PyTorch code on Trainium requires minimal changes, organized below by execution mode and common configuration:
For Eager Mode Execution:
Minimal changes listed below:
Device placement: Change
.to('cuda')to.to('neuron')torch.acceleratorAPI: If your code usestorch.accelerator, no changes are needed (automatic device detection)Mixed precision: Use standard
torch.autocast(device_type="neuron")API with automatic datatype conversion following PyTorch CUDA conventionsDistributed training: Native support for FSDP, DTensor, Tensor Parallelism, and Distributed Data Parallel with no code modifications required, except for sharding configurations which depend on the number of NeuronCores (which can be different from the number of GPUs)
Sharding (Parallelism) Configuration: On Trainium, the unit of distribution is the NeuronCore, the heterogeneous compute unit that powers Trainium. Configure sharding strategies based on available Trainium instance and NeuronCores per Trainium chip, which depends on model and workload requirements. For some parallelism strategies like Tensor Parallelism, you need to specify how many NeuronCores are used for sharding. For other strategies like FSDP, no configuration changes are needed.
For torch.compile:
On top the minimal changes listed in Eager Mode, the following two changes are needed for torch.compile:
Specify
backend="neuron"(Specifically,@torch.compile(backend="neuron"))Remove CUDA-specific parameters like m``ode=”max-autotune-no-cudagraphs”``
Q: What is NKI and when and how should I use it?
NKI (Neuron Kernel Interface) is TorchNeuron’s kernel programming interface for creating custom operators optimized for Trainium hardware. NKI uses similar definition and registration patterns as Triton, providing a familiar workflow for developers.
When to use NKI:
For performance optimization requiring low-level hardware control
For novel research requiring operations not yet expressible in standard PyTorch
How to use NKI:
Import
torch_neuronxDefine kernels using
@nki.jitdecorator for low-level hardware controlRegister as PyTorch operators with
@nki_opdecorator for seamless integrationProvide explicit type signatures like
(x: torch.Tensor) -> torch.TensorFor training, add autograd support via
register_autograd()method for custom backward passes
NKI kernels work in both eager execution and torch.compile, integrating seamlessly with PyTorch’s custom op registration system.
Q: Do I need to import torch_neuronx when not using NKI?
No, the torch_neuronx import is only needed when using NKI kernels (via nki.jit).
In PyTorch 2.9, PyTorch introduced a feature that allows custom backends to autoload their device and thereby register their backend. TorchNeuron follows the same setup as mentioned, allowing us to get rid of the import for device registration. For more details, see Autoloading Out-of-Tree Extension.
Q: What changes are needed to run TorchTitan on Trainium?
Running TorchTitan on Trainium requires minimal code changes:
For Eager Mode:
Zero code changes required. TorchTitan’s automatic device detection discovers Trainium hardware automatically.
For torch.compile:
Minimal changes required:
Specify
backend="neuron"Remove CUDA-specific parameters
For Mixed Mode (Eager + torch.compile):
When combining eager execution with components that use
torch.compile(like FlexAttention), apply thetorch.compilechanges only to those specific components.
Parallelism Configuration:
Configure sharding strategy based on your hardware. For example, set
NGPU=64for 16 Trainium2 chips (4 NeuronCores per chip). On Trainium, the unit of distribution is the NeuronCore, and you must specify how many NeuronCores are used based on your model and parallelism strategy.
Open Source & Development FAQ#
Q: Will TorchNeuron be fully open source with GitHub-first development?
Yes. We are setting up the infrastructure for GitHub-first development in early 2026.
Q: Will TorchNeuron have open source CI/CD and nightly benchmarks similar to other PyTorch backends?
Yes, TorchNeuron will have open source CI/CD before it reaches GA level same way we supported and enable PyTorch CI/CD for Aarch64 on graviton. We will provide similar testing and benchmarking infrastructure comparable to PyTorch CUDA, ROCm, and Intel XPU.
Q: When will TorchNeuron move from out-of-tree to in-tree in the main PyTorch repository?
Our ultimate goal is to move in-tree. However, we are starting as out-of-tree as it is the fastest way to provide value to our customers and allow us faster iteration in early life. Regardless of placement, our goal is to have full CI/CD integration as part of PyTorch’s CI/CD infrastructure, even while out-of-tree. We are actively in discussions with PyTorch on the best path forward.
Torch.compile FAQ#
Q: Does the Neuron Backend for TorchDynamo use Inductor?
This may evolve in future releases. For this release, the Neuron Backend for TorchDynamo provides native torch.compile support without using Inductor.
Q: What does the Neuron TorchDynamo backend generate: kernels or hardware instructions?
The Neuron backend generates Neuron IR, which may include NKI kernels passed as custom ops in the FX graphs. The Neuron Compiler then generates Trainium instructions from the IR.
Q: Does Neuron TorchDynamo Backend support overlapping compute and communication operations?
The overlapping functionality is supported by the Neuron Compiler itself, and not by TorchDynamo backend.
Q: When using torch.compile, does TorchNeuron support graph breaks?
Yes, the Neuron TorchDynamo backend supports graph breaks.
Q: When using torch.compile, does TorchNeuron have equivalents to CUDA graphs and CUDA graph trees?
Not in the initial release. We are considering equivalent constructs for future releases.
Q: Can I compile my model using torch.compile on a compute instance without Trainium hardware?
No. The initial release requires compilation on Trainium2 or Trainium3 (Trn2 or Trn3) instances. Future releases will support compilation on non-Trainium instances.
Eager Mode Execution FAQ#
Q: How does eager mode work on TorchNeuron? What is Adaptive Eager Execution, and how can operations be both dispatched individually and fused for performance?
Execution Model:
In PyTorch eager mode on TorchNeuron, operations are executed immediately as they are encountered in the Python code, following the same “define-by-run” paradigm where each operation is dispatched one at a time through PyTorch’s dispatcher to the Neuron backend.
Neuron Asynchronous Execution:
Peeking into the details, Neuron operations are enqueued to the device asynchronously allowing the Python interpreter to continue issuing subsequent operations while previous Neuron operations may still be executing. PyTorch automatically performs necessary synchronization when copying data between host and devices or when accessing tensor values, making the effect of asynchronous computation transparent to the user since each device executes operations in the order they are queued.
Adaptive Eager Execution:
When the user is not debugging or inspecting tensors, TorchNeuron introduces Adaptive Eager Execution as an optimization. In PyTorch, the dispatcher queues operations on the backend for execution while the Python code continues running ahead. This allows multiple operations to be queued up simultaneously. TorchNeuron takes advantage of this mechanism by analyzing sequences of queued operators and fusing them into single operators based on fusion heuristics. These fused operations are then dispatched as single operator calls, improving performance while maintaining the same execution order, numerical accuracy, and determinism as non-fused execution.
Debugging and Tensor Inspection:
Whenever a user wants to print a tensor, just like any other backend, Neuron synchronizes at the operation where that tensor is needed and performs a device-to-host copy. This synchronization and copy mechanism applies the same way for fused ops when Adaptive Eager Execution is enabled.
In the context of Adaptive Eager Execution, printing operations may determine fusion boundaries. If printing occurs after an operation that would normally be fused with subsequent operations, fusion will not happen at that point to ensure the requested tensor value is available for inspection.
When torch.use_deterministic_algorithms() or torch.set_deterministic_debug_mode() is called, TorchNeuron will ensure reproducible order of execution and Adaptive Eager Execution optimizations are disabled.
Q: Where are the TorchNeuron kernels implemented for eager mode execution?
ATen implementations and kernels are part of the Neuron backend for eager mode. Currently, TorchNeuron is an out-of-tree backend. When TorchNeuron becomes an in-tree backend, those implementations will be part of the main PyTorch repository.
Distributed Training FAQ#
Q: Which FSDP implementation does TorchNeuron support FSDP1, FSDP2, or SimpleFSDP?
For eager mode, TorchNeuron supports all three: FSDPv1, FSDPv2, and SimpleFSDP. For torch.compile, TorchNeuron follows the PyTorch community recommendation and supports SimpleFSDP as it is more compiler-friendly, see SimpleFSDP: Simpler Fully Sharded Data Parallel with torch.compile.
Q: Does TorchNeuron support activation checkpointing?
Yes. TorchNeuron supports activation checkpointing.
Q: Does TorchNeuron support passing a mixed precision policy directly to FSDP, or do I need to use the autocast API?
Both are supported. You can pass a mixed precision policy directly to FSDP or use the autocast API; it is up to the user to decide.
General FAQ#
Q: Does TorchNeuron support native PyTorch MoE (Mixture of Experts) operations?
Yes, torch native MoE ops will be supported from first release, including torch._scaled_grouped_mm, torch._grouped_mm, and MoE Dispatch/Combine operations. First TorchNeuron release already comes with GPT-OSS support that covers all this.
torch.all_to_all_vdev_2d and torch.all_to_all_vdev_2d_offset (MoE Dispatch/Combine ops) will be supported in future releases.
Q: What is the timeline for supporting PyTorch Foundation libraries like torchcomms, monarch, torchforge, and torchao?
We are actively evaluating support for these libraries now. Our goal is to support all of them over the next couple of quarters.
Q: Can NeuronCores on the same Trainium chip share HBM memory?
Yes. HBM can be shared between the multiple NeuronCores on a single Trainium chip. However, depending on the Trainium generation, the available bandwidth of the NeuronCore and HBM could vary depending on affinity.
Appendix#
While historically PyTorch used autograd function style, that approach is less recommended:
# sin_autograd.py
# sine using NKI kernels, registered via torch.autograd.Function (not recommended)
import torch
from torch_neuronx import nki
# Declaring and implementing NKI kernels
@nki.jit
def sin_kernel(in_ptr0, out_ptr):
import nki.language as nl
input_tile = nl.load(in_ptr0[0:128])
output_tile = nl.sin(input_tile)
nl.store(out_ptr[0:128], value=output_tile)
@nki.jit
def cos_kernel(in_ptr0, out_ptr):
import nki.language as nl
input_tile = nl.load(in_ptr0[0:128])
output_tile = nl.cos(input_tile)
nl.store(out_ptr[0:128], value=output_tile)
# after this line, there is no NKI code, just native PyTorch
# Create autograd function
class NKI_sin(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
output = torch.empty_like(x)
# Here we call the nki kernel for sin
sin_kernel(x, output)
return output
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
cos_result = torch.empty_like(x)
# Here we call the nki kernel for cos
cos_kernel(x, cos_result) # cos is derivative of sin
return grad_output * cos_result
# User-facing function
def custom_sin(x):
"""Sin with cosine as backward pass."""
return NKI_sin.apply(x)
# Test
if __name__ == "__main__":
x = torch.randn(128, device="neuron", requires_grad=True)
# Forward pass, which call forward() -> sin_kernel()
y = custom_sin(x)
# Backward pass
loss = y.sum()
# autograd automatically calls backward() -> cos_kernel()
loss.backward()
# Verify
expected_forward = torch.sin(x)
expected_grad = torch.cos(x.detach())
print("Testing accuracy of sin custom op, using autograd function style")
assert torch.allclose(y, expected_forward, atol=1e-5)
assert torch.allclose(x.grad, expected_grad, atol=1e-5)
print("✅ Forward: sin kernel")
print("✅ Backward: cos kernel")
print("✅ Gradients match!")
Resources and More Information#
This document is relevant for: Trn2, Trn3