
This document is relevant for: Inf2, Trn1
Custom Operators API Reference Guide [Beta]#
This page provides the documentation for the C++ API available to creators of Neuron custom C++ operators (see Neuron Custom C++ Operators [Beta]).
Tensor Library#
The tensor library used for Neuron custom C++ operators is based upon the PyTorch ATen tensor library. This includes the core Tensor class as well as select operations defined below. Users need to include the <torch/torch.h> header to access the tensor library. A small example of using the tensor library looks as follows.
#include <torch/torch.h>
...
torch::Tensor a = torch::zeros({32, 32, 3}, torch::kFloat);
Tensor Factory Functions#
The tensor factory functions provide different means for creating new tensors.
They each take in a size argument that specifies the size of each dimension of the tensor created (with the exception of eye, which takes in two int64’s and creates a strictly 2-dimensional identity matrix.)
c10::TensorOptions allows the specification of optional properties for the tensor being created. Currently, only the dtype property has an effect on tensor construction, and it must be specified. Other properties, such as layout may be supported in the future.
The example above shows a common way to use factory functions.
The following dtypes are supported:
torch::kFloat
torch::kBFloat16
torch::kHalf
torch::kInt
torch::kChar
torch::kShort
torch::kByte
-
torch::Tensor empty(torch::IntArrayRef size, c10::TensorOptions options)#
Creates a tensor filled with uninitialized data, with the specified size and options. Slightly faster than other factory functions since it skips writing data to the tensor.
-
torch::Tensor full(torch::IntArrayRef size, const Scalar &fill_value, c10::TensorOptions options)#
Creates a tensor filled with the specified
fill_value, with the specified size and options.
-
torch::Tensor zeros(torch::IntArrayRef size, c10::TensorOptions options)#
Creates a tensor filled with zeros, with the specified size and options.
-
torch::Tensor ones(torch::IntArrayRef size, c10::TensorOptions options)#
Creates a tensor filled with ones, with the specified size and options.
-
torch::Tensor eye(int64_t n, int64_t m, c10::TensorOptions options)#
Creates a 2-D tensor with ones on the diagonal and zeros elsewhere.
Tensor Operation Functions#
The tensor library provides commonly used operations defined below. The tensor operation functions do not support broadcasting; the shape of the operands must match if applicable.
The library provides two styles of functions for each tensor operation. For functions ending with _out, a tensor with the proper size must be provided to which the output is written. This is illustrated in the example below.
torch::exp_out(t_out, t_in);
Alternatively, for functions that do not end in _out, a new tensor that contains the results of the operation is allocated and returned as seen in the example below.
torch::Tensor t_out = torch::exp(t_in);
Warning
Only operations that are documented below are supported.
-
torch::Tensor &abs_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor abs(torch::Tensor &self)#
Computes the absolute value of each element in
self.
-
torch::Tensor &ceil_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor ceil(torch::Tensor &self)#
Computes the ceiling of the elements of
self, the smallest integer greater than or equal to each element.
-
torch::Tensor &floor_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor floor(torch::Tensor &self)#
Computes the floor of the elements of
self, the largest integer less than or equal to each element.
-
torch::Tensor &sin_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor sin(torch::Tensor &self)#
Computes the sine value of the elements of
self.
-
torch::Tensor &cos_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor cos(torch::Tensor &self)#
Computes the cosine value of the elements of
self.
-
torch::Tensor &tan_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor tan(torch::Tensor &self)#
Computes the tangent value of the elements of
self.
-
torch::Tensor &log_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor log(torch::Tensor &self)#
Computes the natural logarithm of the elements of
self.
-
torch::Tensor &log2_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor log2(torch::Tensor &self)#
Computes the base-2 logarithm of the elements of
self.
-
torch::Tensor &log10_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor log10(torch::Tensor &self)#
Computes the base-10 logarithm of the elements of
self.
-
torch::Tensor &exp_out(torch::Tensor &result, torch::Tensor &self)#
-
torch::Tensor exp(torch::Tensor &self)#
Computes the exponential of the elements of
self.
-
torch::Tensor &pow_out(torch::Tensor &result, const torch::Tensor &self, const torch::Scalar &exponent)#
-
torch::Tensor &pow_out(torch::Tensor &result, const torch::Scalar &self, const torch::Tensor &exponent)#
-
torch::Tensor &pow_out(torch::Tensor &result, const torch::Tensor &self, const torch::Tensor &exponent)#
-
torch::Tensor pow(const torch::Tensor &self, const torch::Scalar &exponent)#
-
torch::Tensor pow(const torch::Scalar &self, const torch::Tensor &exponent)#
-
torch::Tensor pow(const torch::Tensor &self, const torch::Tensor &exponent)#
Takes the power of each element in
selfwithexponent.
-
torch::Tensor &clamp_out(torch::Tensor &result, const torch::Tensor &self, const torch::Scalar &minval, const torch::Scalar &maxval)#
-
torch::Tensor clamp(const torch::Tensor &self, const torch::Scalar &minval, const torch::Scalar &maxval)#
Clamps all elements in
selfinto the range[minval, maxval].
-
torch::Tensor &add_out(torch::Tensor &result, const torch::Tensor &self, const torch::Scalar &other, const torch::Scalar &alpha = 1)#
-
torch::Tensor &add_out(torch::Tensor &result, const torch::Tensor &self, const torch::Tensor &other, const torch::Scalar &alpha = 1)#
-
torch::Tensor add(const torch::Tensor &self, const torch::Scalar &other, const torch::Scalar &alpha = 1)#
-
torch::Tensor add(const torch::Tensor &self, const torch::Tensor &other, const torch::Scalar &alpha = 1)#
Adds
other, scaled byalpha, toinput,
-
torch::Tensor &sub_out(torch::Tensor &result, const torch::Tensor &self, const torch::Scalar &other, const torch::Scalar &alpha = 1)#
-
torch::Tensor &sub_out(torch::Tensor &result, const torch::Tensor &self, const torch::Tensor &other, const torch::Scalar &alpha = 1)#
-
torch::Tensor sub(const torch::Tensor &self, const torch::Tensor &other, const torch::Scalar &alpha = 1)#
-
torch::Tensor sub(const torch::Tensor &self, const torch::Scalar &other, const torch::Scalar &alpha = 1)#
Subtracts
other, scaled byalpha, toinput,
-
torch::Tensor &mul_out(torch::Tensor &result, const torch::Tensor &self, const torch::Scalar &other)#
-
torch::Tensor &mul_out(torch::Tensor &result, const torch::Tensor &self, const torch::Tensor &other)#
-
torch::Tensor mul(const torch::Tensor &self, const torch::Scalar &other)#
-
torch::Tensor mul(const torch::Tensor &self, const torch::Tensor &other)#
Multiplies
selfbyother.
-
torch::Tensor &div_out(torch::Tensor &result, const torch::Tensor &self, const torch::Scalar &other)#
-
torch::Tensor &div_out(torch::Tensor &result, const torch::Tensor &self, const torch::Tensor &other)#
-
torch::Tensor div(const torch::Tensor &self, const torch::Scalar &other)#
-
torch::Tensor div(const torch::Tensor &self, const torch::Tensor &other)#
Divides
selfbyother.
Note
For tensor-tensor bitwise operations, all the bitwise operations are elementwise between two tensors. For scalar-tensor bitwise operations, the scalar is casted to the datatype of the tensor before computing the bitwise operation.
-
torch::Tensor &bitwise_and_out(torch::Tensor &result, const torch::Tensor &self, const torch::Tensor &other)#
-
torch::Tensor &bitwise_and_out(torch::Tensor &result, const torch::Tensor &self, const torch::Scalar &other)#
-
torch::Tensor &bitwise_and_out(torch::Tensor &result, const torch::Scalar &self, const torch::Tensor &other)#
-
torch::Tensor bitwise_and(const torch::Tensor &self, const torch::Tensor &other)#
-
torch::Tensor bitwise_and(const torch::Tensor &self, const torch::Scalar &other)#
-
torch::Tensor bitwise_and(const torch::Scalar &self, const torch::Tensor &other)#
Computes the bitwise AND of
selfandother. The input tensors must be of integral types.
-
torch::Tensor &bitwise_or_out(torch::Tensor &result, const torch::Tensor &self, const torch::Tensor &other)#
-
torch::Tensor &bitwise_or_out(torch::Tensor &result, const torch::Tensor &self, const torch::Scalar &other)#
-
torch::Tensor &bitwise_or_out(torch::Tensor &result, const torch::Scalar &self, const torch::Tensor &other)#
-
torch::Tensor bitwise_or(const torch::Tensor &self, const torch::Tensor &other)#
-
torch::Tensor bitwise_or(const torch::Tensor &self, const torch::Scalar &other)#
-
torch::Tensor bitwise_or(const torch::Scalar &self, const torch::Tensor &other)#
Computes the bitwise OR of
selfandother. The input tensors must be of integral types.
-
torch::Tensor &bitwise_not_out(torch::Tensor &result, const torch::Tensor &self)#
-
torch::Tensor bitwise_not(torch::Tensor &result, const torch::Tensor &self)#
Computes the bitwise NOT of
self. The input tensor must be of integral types.
Class torch::Tensor#
Constructors#
Users should not call the Tensor constructor directly but instead use one of the Tensor factory functions.
Member Functions#
-
template<typename T, size_t N>
TensorAccessor<T, N, true> accessor() const &# Return a
TensorAccessorfor element-wise random access of a Tensor’s elements. Scalar type and dimension template parameters must be specified. This const-qualified overload returns a read-onlyTensorAccessor, preventing the user from writing to Tensor elements. See the Tensor Accessors section below for more details.
-
template<typename T, size_t N>
TensorAccessor<T, N, false> accessor() &# Return a
TensorAccessorfor element-wise random access of a Tensor’s elements. Scalar type and dimension template parameters must be specified. This non-const-qualified overload returns aTensorAccessorthat can be used to both read and write to Tensor elements. See the Tensor Accessors section below for more details.
-
template<typename T>
TensorReadStreamAccessor<T> read_stream_accessor() const &# Opens a streaming accessor for read on a tensor. Template parameter
Tis the scalar type of the tensor data. See Streaming Accessors section below for more details.
-
template<typename T>
TensorWriteStreamAccessor<T> write_stream_accessor() &# Opens a streaming accessor for write on a tensor. Template parameter
Tis the scalar type of the tensor data. See Streaming Accessors section below for more details.
-
CoherencyEnforcer::Policy get_accessor_coherence_policy() const#
Get the Tensor accessor coherence policy. See Coherence section below for more details.
-
void set_accessor_coherence_policy(CoherencyEnforcer::Policy policy) const#
Set the Tensor accessor coherence policy. See Coherence section below for more details.
-
TensorTcmAccessor<true> tcm_accessor() const &#
Opens a TCM accessor on a tensor. This const-qualified overload returns a read-only
TensorTcmAccessor, preventing the user from writing to Tensor elements. See TCM Accessor section below for more details.
-
TensorTcmAccessor<false> tcm_accessor() &#
Opens a TCM accessor on a tensor. This non-const-qualified overload returns a
TensorTcmAccessorthat can be used to both read and write to Tensor elements. See TCM Accessor section below for more details.
-
torch::Tensor &fill_(const torch::Scalar &value) const#
Fill a tensor with the specified value.
Tensor Operators#
-
Tensor &operator=(const Tensor &x) &#
-
Tensor &operator=(Tensor &&x) &#
Assignment operators
Tensor Accessors#
The standard tensor accessor provides element-wise random access to Tensor elements. They can be created by calling Tensor::accessor(). It can be used similarly to the Pytorch ATen version (see https://pytorch.org/cppdocs/notes/tensor_basics.html#cpu-accessors). However, it is not as fast as other methods of accessing a Tensor, such as the streaming accessor or TCM accessor.
Warning
The standard tensor accessors can only be used in single core mode. Using standard tensor accessors in multicore mode is undefined behaviour and is going to cause race condition, yielding incorrect result.
Example Usage#
Element-wise add of two 1D tensors using TensorAccessor.
torch::Tensor tensor_add_compute(const torch::Tensor& t1, const torch::Tensor& t2) {
size_t num_elem = t1.numel();
assert(t1.sizes() == t2.sizes());
torch::Tensor t_out = torch::empty({num_elem}, torch::kFloat);
auto t1_acc = t1.accessor<float, 1>();
auto t2_acc = t2.accessor<float, 1>();
auto t_out_acc = t_out.accessor<float, 1>();
for (size_t i = 0; i < num_elem; i++) {
t_out_acc[i] = t1_acc[i] + t2_acc[i];
}
return t_out;
}
Memory Architecture#
Tensor data is stored in HBM. The various types of accessors enable users to access tensor data from their custom C++ operator code running on the GPSIMD engine.
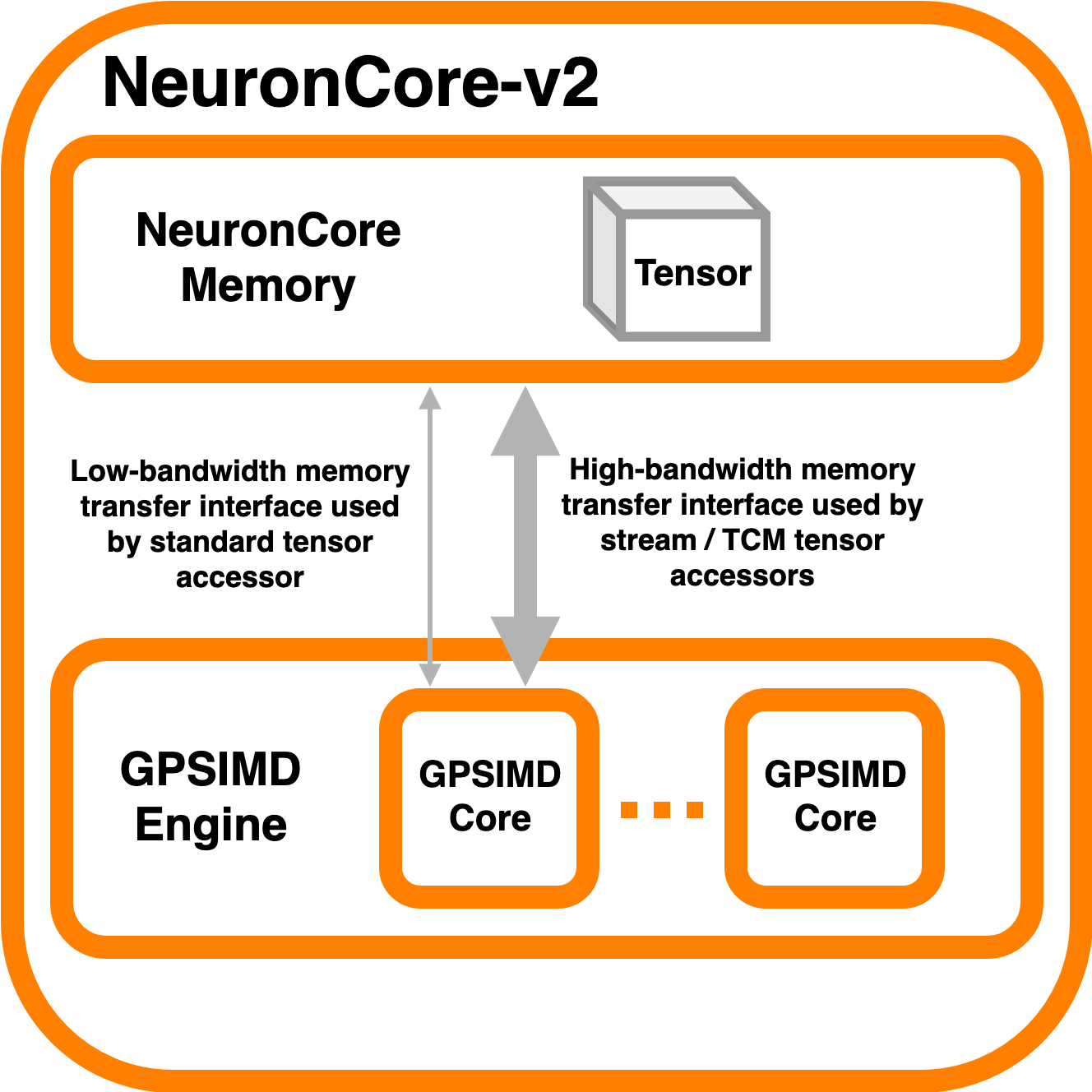
Streaming Accessors#
Streaming accessors provide the user the ability to access Tensor elements in sequential order, faster than the standard tensor accessor. There are two stream accessor classes, one for reading and one for writing. Users should not construct stream accessors directly, but should get them from a Tensor using Tensor::read_stream_accessor and Tensor::write_stream_accessor().
An active stream accessor is defined as a stream accessor that has been instantiated and not yet closed (via the close() method or by going out-of-scope).
The user is responsible for managing stream accessors concurrently accessing the same Tensor. For safest usage, no stream accessor should be active while there is an active TensorWriteStreamAccessor on the same Tensor. The user may either have multiple TensorReadStreamAccessors active on the same Tensor, or only have a single TensorWriteStreamAccessor active on that Tensor. Stream accessors should not be used concurrently with standard tensor accessors on the same Tensor.
An unlimited number of active stream accessors (in total, across all Tensors) are functionally supported, but only up to 4 active stream accessors will be performant. Additional stream accessors beyond the 4th will have performance similar to that of a standard tensor accessor.
Warning
Streaming Accessors can only be used in single core mode. Using streaming accessors in multicore mode is undefined behaviour and is going to cause race condition, yielding incorrect result.
Example Usage#
Element-wise add of two tensors using TensorWriteStreamAccessor and TensorWriteStreamAccessor.
torch::Tensor tensor_add_compute(const torch::Tensor& t1, const torch::Tensor& t2) {
assert(t1.sizes() == t2.sizes());
torch::Tensor t_out = torch::empty(t1.sizes(), torch::kFloat);
auto t1_rd_stm_acc = t1.read_stream_accessor<float>();
auto t2_rd_stm_acc = t2.read_stream_accessor<float>();
auto t_out_wr_stm_acc = t_out.write_stream_accessor<float>();
for (int i = 0; i < t1.numel(); i++) {
auto sum = t1_rd_stm_acc.read() + t2_rd_stm_acc.read();
t_out_wr_stm_acc.write(sum);
}
return t_out;
}
Class torch::TensorWriteStreamAccessor#
-
template<typename T>
class TensorReadStreamAccessor# The class template parameter
Tis the scalar type of the tensor data.
Member Functions#
-
T read()#
Reads from next element in the stream. User is responsible for knowing when to stop reading from
TensorReadStreamAccessor. Reading past the end of the stream or on a closed stream results in undefined behaviour.
-
int close()#
Closes stream. Do not read from the stream after calling
close().
Class torch::TensorWriteStreamAccessor#
-
template<typename T>
class torch::TensorWriteStreamAccessor# The class template parameter
Tis the scalar type of the tensor data.
Member Functions#
-
void write(T value)#
Writes to next element in the stream. Written value is not guaranteed to be written back to the Tensor’s memory until the
TensorWriteStreamAccessorgoes out of scope, or the user explicitly callsclose(). User is responsible for knowing when to stop writing to a stream accessor. Writing past the end of the stream or on a closed stream results in undefined behaviour.
-
int close()
Closes stream. Flushes write data to the
Tensor’s memory. Do not write to the stream after callingclose().
Coherence#
Stream accessors cache Tensor data in GPSIMD tightly-coupled memory (TCM), but do not ensure their caches remain coherent. When exactly they read from or write back to HBM is opaque to the user (except for close() which forces a write back).
The safest way to use them is to ensure that no stream accessor is active (instantiated and not yet closed) while there is an active write stream accessor on the same Tensor. The user should either have multiple read stream accessors active on the same Tensor, or only have a single write stream accessor active on that Tensor.
The standard tensor accessors read/write HBM directly. Therefore, tensor accessors can safely concurrently access the same Tensor, but it is safest not to use them concurrently with stream accessors since HBM isn’t guaranteed to be coherent with the stream accessor caches.
These coarse-grained guidelines are best practices, but it is possible to ignore them with careful usage of the accessors (making sure elements are read before they are written to, elements written to are written back before being read again, etc).
The coherence policy of a Tensor determines what to do when there is potentially incoherent access by an accessor of that Tensor. It can either cause an error, or allow it but print a warning, or do nothing. In the case of the latter two options, it is the user’s responsibility to ensure they carefully use accessors coherently. Coherence policy for Tensors is torch::CoherencyEnforcer::Policy::COHERENT by default, but can be changed using Tensor::set_accessor_coherence_policy().
// class torch::CoherencyEnforcer
enum Policy {
// Enforce a resource is acquired in a way that guarantees coherence
// Causes an error if it encounters potentially incoherent access
COHERENT,
// Allows potentially incoherent access, but will print a warning
INCOHERENT_VERBOSE,
// Allows potentially incoherent access, no error or warnings
INCOHERENT_QUIET
};
TCM Accessor#
TCM accessors provide the fastest read and write performance. TCM accessors allow the user to manually manage copying data between larger, but slower-access HBM to faster GPSIMD tightly-coupled memory (TCM). It may be beneficial to see the diagram under Memory Architecture. Create a TensorTcmAccessor from a Tensor by calling Tensor::tcm_accessor(). Users can allocate and free TCM memory using tcm_malloc() and tcm_free(). Users have access to a 16KB pool of TCM memory. Note the streaming accessors also allocate from this pool (4KB each). TCM accessors do not do any coherence checks.
Note
See Neuron Custom C++ Operators Performance Optimization for a tutorial on how to use TCM accessors.
Example Usage#
Element-wise negate of a tensor using TensorTcmAccessor.
torch::Tensor tensor_negate_compute(const torch::Tensor& t_in) {
size_t num_elem = t_in.numel();
torch::Tensor t_out = torch::empty(t_in.sizes(), torch::kFloat);
static constexpr size_t buffer_size = 1024;
float *tcm_buffer = (float *)torch::neuron::tcm_malloc(sizeof(float) * buffer_size);
if (tcm_buffer != nullptr) {
// tcm_malloc allocated successfully, use TensorTcmAccessor
auto t_in_tcm_acc = t_in.tcm_accessor();
auto t_out_tcm_acc = t_out.tcm_accessor();
for (size_t i = 0; i < num_elem; i += buffer_size) {
size_t remaining_elem = num_elem - i;
size_t copy_size = (remaining_elem > buffer_size) ? buffer_size : remaining_elem;
t_in_tcm_acc.tensor_to_tcm<float>(tcm_buffer, i, copy_size);
for (size_t j = 0; j < copy_size; j++) {
tcm_buffer[j] *= -1;
}
t_out_tcm_acc.tcm_to_tensor<float>(tcm_buffer, i, copy_size);
}
torch::neuron::tcm_free(tcm_buffer);
} else {
// Handle not enough memory...
}
return t_out;
}
TCM Management Functions#
-
void *torch::neuron::tcm_malloc(size_t nbytes)#
Allocate
nbytesbytes of memory from TCM and return pointer to this memory. Upon failure, returns null.
-
void torch::neuron::tcm_free(void *ptr)#
Free memory that was allocated by
tcm_malloc(). Undefined behaviour ifptrwas not returned from a previous call totcm_malloc().
Class torch::TensorTcmAccessor#
-
template<bool read_only>
class torch::TensorTcmAccessor# The
read_onlytemplate parameter controls whether or not you can write to the accessor’sTensor. Aconst Tensorwill return a read-onlyTensorTcmAccessorfromTensor::tcm_accessor().
Member Functions#
-
template<typename T>
void tensor_to_tcm(T *tcm_ptr, size_t tensor_offset, size_t num_elem)# Copy
num_elemelements from the accessor’sTensorstarting at the indextensor_offsetto a TCM buffer starting attcm_ptr. Tensor indexing is performed as if the tensor was flattened. Template parameterTis the scalar type of the tensor data. The TCM buffer’s size should be at leastsizeof(T) * num_elembytes.
-
template<typename T>
void tcm_to_tensor(T *tcm_ptr, size_t tensor_offset, size_t num_elem)# Copy
num_elemelements from a TCM buffer starting attcm_ptrto the accessor’sTensorstarting at the indextensor_offset. Tensor indexing is performed as if the tensor was flattened. The TCM buffer’s size should be at leastsizeof(T) * num_elembytes.
Writing Directly to Output Tensor#
-
torch::Tensor get_dst_tensor()#
Returns a reference to the Custom C++ operator output tensor (return value). If this method is called, it is assumed that data will be written to this output tensor, and the tensor returned from the C++ operator will be ignored. Using this method will improve performance by avoiding additional copying of the return value. See example below for function usage.
// Example of write to get_dst_tensor() torch::Tensor example_kernel(const torch::Tensor& t_in) { size_t num_elem = t_in.numel(); torch::Tensor t_out = get_dst_tensor(); auto t_out_tcm_acc = t_out.tcm_accessor(); float *tcm_buffer = (float *)torch::neuron::tcm_malloc(sizeof(float) * buffer_size); // Populate tcm_buffer with results ... // Write to t_out through tcm_accessor t_out_acc.tcm_to_tensor<float>(tcm_buffer, offset, copy_size); ... }
Using multiple GPSIMD cores#
Note
See Neuron Custom C++ Operators Performance Optimization for a tutorial on how to use multiple GPSIMD cores to execute the Custom C++ Operator
By default, Custom C++ operators target a single core of the GPSIMD-Engine. Performance of Custom C++ operators can be improved by targeting multiple cores. To enable usage of multiple GPSIMD cores, multicore=True should be passed to custom_op.load().
custom_op.load(
name=name,
compute_srcs=compute_srcs,
shape_srcs=shape_srcs,
build_directory=os.getcwd(),
multicore=True
)
Each GPSIMD core executes the same kernel function. The user can control the execution on each core by conditioning the Custom C++ operator logic on the core id (obtained via get_cpu_id() API). This is illustrated in the example below.
Warning
In multicore mode, tensors can only be accessed through TCM accessors. Using regular tensor accessors and streaming accessors are going to yield incorrect result.
The following functions are defined in neuron/neuron-utils.hpp
-
uint32_t get_cpu_id()#
Return the id of the core that the Custom C++ operator is executing on, id is in range
[0, get_cpu_count())
-
uint32_t get_cpu_count()#
Return the total number of available GPSIMD cores.
torch::Tensor example_kernel(const torch::Tensor& t_in) {
size_t num_elem = t_in.numel();
torch::Tensor t_out = get_dst_tensor();
uint32_t cpu_id = get_cpu_id();
uint32_t cpu_count = get_cpu_count();
uint32_t partition = num_elem / cpu_count;
float *tcm_buffer = (float *)torch::neuron::tcm_malloc(sizeof(float) * buffer_size);
// Populate tcm_buffer with desired results
...
// Write to t_out with a offset computed from cpu_id and cpu_count
t_out_tcm_acc.tcm_to_tensor<float>(tcm_buffer, partition*cpu_id, copy_size);
...
}
Return Value Handling#
When using multiple GPSIMD cores, the get_dst_tensor() API must be used to write the return value of the Custom C++ operators. Data not written to the tensor reference returned by get_dst_tensor(), or not invoking get_dst_tensor() will result in undefined behavior. The user is responsible for writing the appropriate portion of the output reference tensor from a given GPSIMD core. Since there is no synchronization between GPSIMD cores, it is advised that each GPSIMD core writes to a mutually exclusive partition of the output reference tensor.
printf()#
Custom C++ operators support the use of C++’s printf() to send information to the host’s terminal. Using printf() is the recommended approach to functional debug. With it, the programmer can check the value of inputs, outputs, intermediate values, and control flow within their operator.
Usage#
To use printf() within a Custom C++ operator, the programmer must set the following environment variables before running their model in order to receive the messages printed by their operator:
Name |
Description |
Type |
Value to Enable printf |
Default Value |
|---|---|---|---|---|
|
Runtime log verbose level |
String |
At least |
See (Neuron Runtime configuration) for more options. |
|
Size of the printf output buffer, in bytes |
Integer |
Any power of two that is equal to or less than |
Recommend setting a value of |
Within a Custom C++ operator, printf() can be used as normal from within a C++ program. For more information, consult a reference such as (https://cplusplus.com/reference/cstdio/printf/)
Example#
#include <torch/torch.h>
#include <stdio.h> // Contains printf()
torch::Tensor tensor_negate_compute(const torch::Tensor& t_in) {
size_t num_elem = t_in.numel();
torch::Tensor t_out = torch::zeros({num_elem}, torch::kFloat);
auto t_in_acc = t_in.accessor<float, 1>();
auto t_out_acc = t_out.accessor<float, 1>();
for (size_t i = 0; i < num_elem; i++) {
float tmp = -1 * t_in_acc[i];
printf("Assigning element %d to a value of %f\n", i, tmp);
t_out_acc[i] = tmp;
}
return t_out;
}
Print statements then appear on the host’s terminal with a header message prepended:
2023-Jan-26 00:25:02.0183 4057:4131 INFO TDRV:pool_stdio_queue_consume_all_entries Printing stdout from GPSIMD:
Assigning element 0 to a value of -1.000000
Assigning element 1 to a value of -2.000000
Assigning element 2 to a value of -3.000000
Assigning element 3 to a value of -4.000000
Assigning element 4 to a value of -5.000000
Assigning element 5 to a value of -6.000000
Assigning element 6 to a value of -7.000000
Assigning element 7 to a value of -8.000000
Limitations#
Performance: using
printf()significantly degrades the operator’s performance.The programmer can disable it by unsetting
NEURON_RT_GPSIMD_STDOUT_QUEUE_SIZE_BYTESor setting it to 0.We recommend that you disable
printf()if you are running the model in a performance-sensitive context.
To maximize performance, remove calls to
printf()from within the operator.Even if
printf()is disabled, calling the function incurs overhead.
Buffer size: output from
printf()is buffered during model execution and read by the Neuron runtime after execution.The model can still execute successfully if you overflow the buffer.
Overflowing the buffer causes the oldest data in the buffer to be overwritten.
Print statements are processed and printed to the host’s terminal at the end of model execution, not in real time.
printf()is only supported in single core mode, or on GPSIMD core 0 only when using multiple GPSIMD cores.
Library Limitations#
Tensors passed into and returned from CustomOp functions can either have up to 8 dimensions where the maximum size of each dimension is 65535, or up to 4 dimensions where the maximum size of each dimension is 4294967295.
When using multiple GPSIMD cores, only
TensorTcmAccessoris supported. Usage of other accessors results in undefined behaviour.Each model can only have one CustomOp library, and the library can have 10 functions registered. For more information on function registration in PyTorch, see Implementing an operator in C++ in the Neuron Custom C++ Operators Developer Guide [Beta].
However, models using
torch.sortcannot have any CustomOps.
This document is relevant for: Inf2, Trn1