
This document is relevant for: Trn2, Trn3
Transpose2D#
In this tutorial, we transpose a tensor along two of its axes using NKI. In doing so, we learn about:
The NKI syntax and programming model.
Multi-dimensional memory address patterns in NKI.
As background, there are two main types of transposition in NKI:
Transposition between the partition-dimension axis and one of the free-dimension axes, which is achieved via the
nki.isa.nc_transposeinstruction.Transposition between two axes on the free-dimension, which is achieved via a
nki.isa.tensor_copyinstruction, with indexing manipulation in the free axis to re-arrange the data.
In this example, we’ll focus on the second case: consider a
three-dimensional input tensor [P, F1, F2], where the P axis is mapped
to the different SBUF partitions and the F1 and F2 axes are
flattened and placed in each partition, with F1 being the major
dimension. Our goal in this example is to transpose the F1 and
F2 axes with a parallel dimension P,
to re-arrange the data within each partition. Figure
below illustrates the input and output tensor layouts.
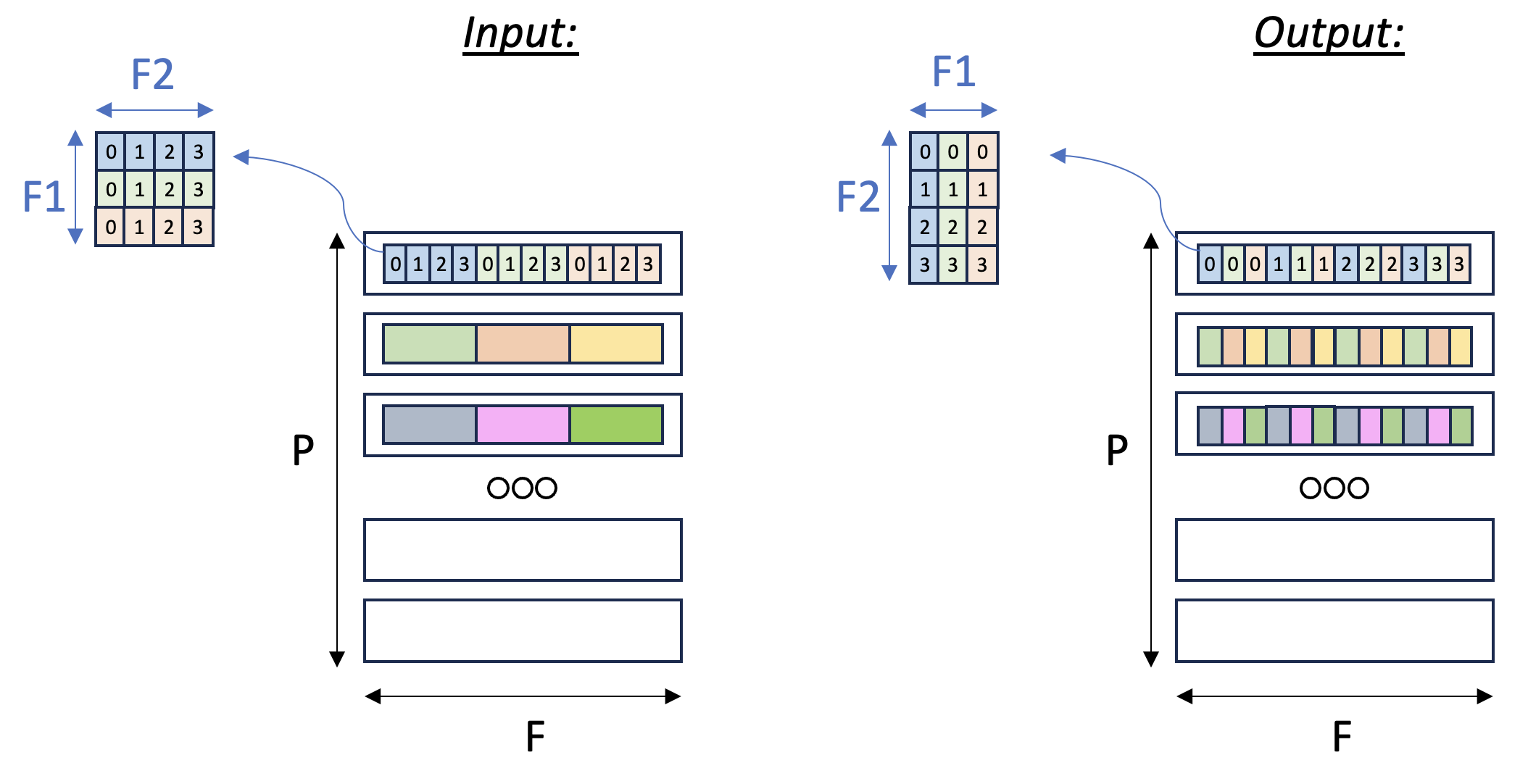
Fig. 24 Tensor F1:F2 Transpose#
PyTorch#
Compute kernel#
1import nki
2import nki.language as nl
3import nki.isa as nisa
4
5
6@nki.jit
7def tensor_transpose2D_kernel_(in_tensor, shape2D):
8 """
9 NKI kernel to reorder the elements on axis[1] of the input tensor.
10
11 Every row of the input tensor is a flattened row-major 2D matrix.
12 The shape2D argument defines the dimensions of the flattened matrices (#rows,#cols).
13 Our goal in this kernel is to transpose these flattened 2D matrices, i.e. make them (#cols,#rows).
14
15 Example:
16 in_tensor = [a0,a1,a2,a3,b0,b1,b2,b3,c0,c1,c2,c3]
17 shape2D = (3,4)
18 this means that in_tensor has 3 rows and 4 columns, i.e. can be represented as:
19 [a0,a1,a2,a3]
20 [b0,b1,b2,b3]
21 [c0,c1,c2,c3]
22 after transpose, we expect to get:
23 [a0,b0,c0]
24 [a1,b1,c1]
25 [a2,b2,c2]
26 [a3,b3,c3]
27 Thus, out_tensor is expected to be [a0,b0,c0,a1,b1,c1,a2,b2,c2,a3,b3,c3]
28
29 Args:
30 in_tensor: an input tensor
31 shape2D: tuple representing the dimensions to be transposed: (#rows, #cols)
32 """
33 out_tensor = nl.ndarray(in_tensor.shape, dtype=in_tensor.dtype,
34 buffer=nl.shared_hbm)
35 # Gather input shapes
36 sz_p, _ = in_tensor.shape
37
38 # Load input data from external memory to on-chip memory
39 in_tile = nl.ndarray(in_tensor.shape, dtype=in_tensor.dtype, buffer=nl.sbuf)
40 nisa.dma_copy(dst=in_tile, src=in_tensor)
41
42 # Performing f1/f2 transpose
43 # ==========================
44 # The desired transpose pattern is provided as an input:
45 sz_f1, sz_f2 = shape2D
46
47 # Perform the transposition via element-wise SBUF-to-SBUF copies
48 # with index arithmetic to scatter elements into transposed positions.
49 # RHS traverses an F1 x F2 matrix in row major order
50 # LHS traverses an F2 x F1 (transposed) matrix in row major order
51 out_tile = nl.ndarray(shape=(sz_p, sz_f2*sz_f1), dtype=in_tensor.dtype,
52 buffer=nl.sbuf)
53 for i_f1 in nl.affine_range(sz_f1):
54 for i_f2 in nl.affine_range(sz_f2):
55 nisa.tensor_copy(dst=out_tile[:, nl.ds(i_f2*sz_f1+i_f1, 1)],
56 src=in_tile[:, nl.ds(i_f1*sz_f2+i_f2, 1)])
57
58 # Finally, we store out_tile to external memory
59 nisa.dma_copy(dst=out_tensor, src=out_tile)
60
61 return out_tensor
Launching kernel and testing correctness#
To execute the kernel, we prepare tensors a and call tensor_transpose2D_kernel_:
1import torch
2import torch_xla
3
4if __name__ == "__main__":
5 device = torch_xla.device()
6
7 P, X, Y = 5, 3, 4
8 a = torch.arange(P*X*Y, dtype=torch.int8).reshape((P, X*Y)).to(device=device)
9 a_t_nki = torch.zeros((P, Y*X), dtype=torch.int8).to(device=device)
10
11 a_t_nki = tensor_transpose2D_kernel_(a, (X, Y))
12
13 a_cpu = torch.arange(P*X*Y, dtype=torch.int8).reshape((P, X*Y))
14 a_t_torch = torch.transpose(a_cpu.reshape(P, X, Y), 1, 2).reshape(P, X * Y).to(device=device)
15
16 print(a, a_t_nki, a_t_torch)
17
18 allclose = torch.allclose(a_t_torch, a_t_nki)
19 if allclose:
20 print("NKI and PyTorch match")
21 else:
22 print("NKI and PyTorch differ")
23
24 assert allclose
JAX#
Compute kernel#
We can reuse the same NKI compute kernel defined for PyTorch above.
1import nki
2import nki.language as nl
3import nki.isa as nisa
4
5
6@nki.jit
7def tensor_transpose2D_kernel_(in_tensor, shape2D):
8 """
9 NKI kernel to reorder the elements on axis[1] of the input tensor.
10
11 Every row of the input tensor is a flattened row-major 2D matrix.
12 The shape2D argument defines the dimensions of the flattened matrices (#rows,#cols).
13 Our goal in this kernel is to transpose these flattened 2D matrices, i.e. make them (#cols,#rows).
14
15 Example:
16 in_tensor = [a0,a1,a2,a3,b0,b1,b2,b3,c0,c1,c2,c3]
17 shape2D = (3,4)
18 this means that in_tensor has 3 rows and 4 columns, i.e. can be represented as:
19 [a0,a1,a2,a3]
20 [b0,b1,b2,b3]
21 [c0,c1,c2,c3]
22 after transpose, we expect to get:
23 [a0,b0,c0]
24 [a1,b1,c1]
25 [a2,b2,c2]
26 [a3,b3,c3]
27 Thus, out_tensor is expected to be [a0,b0,c0,a1,b1,c1,a2,b2,c2,a3,b3,c3]
28
29 Args:
30 in_tensor: an input tensor
31 shape2D: tuple representing the dimensions to be transposed: (#rows, #cols)
32 """
33 out_tensor = nl.ndarray(in_tensor.shape, dtype=in_tensor.dtype,
34 buffer=nl.shared_hbm)
35 # Gather input shapes
36 sz_p, _ = in_tensor.shape
37
38 # Load input data from external memory to on-chip memory
39 in_tile = nl.ndarray(in_tensor.shape, dtype=in_tensor.dtype, buffer=nl.sbuf)
40 nisa.dma_copy(dst=in_tile, src=in_tensor)
41
42 # Performing f1/f2 transpose
43 # ==========================
44 # The desired transpose pattern is provided as an input:
45 sz_f1, sz_f2 = shape2D
46
47 # Perform the transposition via element-wise SBUF-to-SBUF copies
48 # with index arithmetic to scatter elements into transposed positions.
49 # RHS traverses an F1 x F2 matrix in row major order
50 # LHS traverses an F2 x F1 (transposed) matrix in row major order
51 out_tile = nl.ndarray(shape=(sz_p, sz_f2*sz_f1), dtype=in_tensor.dtype,
52 buffer=nl.sbuf)
53 for i_f1 in nl.affine_range(sz_f1):
54 for i_f2 in nl.affine_range(sz_f2):
55 nisa.tensor_copy(dst=out_tile[:, nl.ds(i_f2*sz_f1+i_f1, 1)],
56 src=in_tile[:, nl.ds(i_f1*sz_f2+i_f2, 1)])
57
58 # Finally, we store out_tile to external memory
59 nisa.dma_copy(dst=out_tensor, src=out_tile)
60
61 return out_tensor
Launching kernel and testing correctness#
To execute the kernel, we prepare array a and call tensor_transpose2D_kernel_:
1import jax
2import jax.numpy as jnp
3
4if __name__ == "__main__":
5 P, X, Y = 5, 37, 44
6 a = jax.random.uniform(jax.random.PRNGKey(42), (P, X * Y))
7 a_t_nki = tensor_transpose2D_kernel_(a, shape2D=(X, Y))
8
9 a_t_jax = jnp.transpose(a.reshape(P, X, Y), axes=(0, 2, 1)).reshape(P, X * Y)
10 print(a, a_t_nki, a_t_jax)
11
12 allclose = jnp.allclose(a_t_jax, a_t_nki)
13 if allclose:
14 print("NKI and JAX match")
15 else:
16 print("NKI and JAX differ")
17
18 assert allclose
Note
We pass shape2D as kwargs to pass the shape as a compile-time constant
to the kernel function.
Download All Source Code#
Click the links to download source code of the kernels and the testing code discussed in this tutorial.
NKI baremetal implementation:
transpose2d_nki_kernels.py- PyTorch implementation:
transpose2d_torch.py You must also download
transpose2d_nki_kernels.pyinto the same folder to run this PyTorch script.
- PyTorch implementation:
- JAX implementation:
transpose2d_jax.py You must also download
transpose2d_nki_kernels.pyinto the same folder to run this JAX script.
- JAX implementation:
You can also view the source code in the GitHub repository nki_samples
Example usage of the scripts:#
Run NKI baremetal implementation:
python3 transpose2d_nki_kernels.py
Run PyTorch implementation:
python3 transpose2d_torch.py
Run JAX implementation:
python3 transpose2d_jax.py
This document is relevant for: Trn2, Trn3