
This document is relevant for: Trn2, Trn3
AWS Neuron Dynamic Resource Allocation (DRA)#
What is DRA?#
Prior to Kubernetes 1.33, Kubernetes used device plugins for resource management. The Neuron device plugin implements the device plugin interface to allow Kubernetes scheduler to manage Neuron resources. However, the device plugin framework only tracks device count—the scheduler cannot see device attributes. Due to this limitation, the framework cannot natively facilitate attribute-based filtering during device selection. For example, the default Kubernetes scheduler prior to DRA cannot support allocation of connected devices without additional mechanisms such as a scheduler extension.
Dynamic Resource Allocation (DRA) is a new framework for advanced resource management that addresses this limitation. DRA enables the scheduler to see the device attributes, allowing workloads to select devices based on specific attributes and achieve topology aware allocation. Hardware vendors determine which attributes are published for their hardware. The AWS Neuron DRA driver implements the kubelet plugin for DRA for AWS Trainium instances.
For more information on DRA, refer to Kubernetes Dynamic Resource Allocation.
Where can I get the Neuron DRA driver and resource templates?#
To review and download the individual resource claim templates, visit this page:
What are the benefits of using DRA over device plugin?#
Reduced developer complexity
Device plugin-based workloads use node labels along with request and limits to allocate right resources. Example:
Worker:
replicas: 4
template:
spec:
containers:
- image: <aws-account-id>.dkr.ecr.us-west-2.amazonaws.com/neuronx_nemo:latest
name: mpitest
imagePullPolicy: Always
resources:
limits:
aws.amazon.com/neuron: "16"
vpc.amazonaws.com/efa: "16"
requests:
aws.amazon.com/neuron: "16"
vpc.amazonaws.com/efa: "16"
volumeMounts:
- name: dshm
mountPath: /dev/shm
volumes:
- name: dshm
emptyDir:
medium: Memory
DRA introduces ResourceClaim and ResourceClaimTemplates which provide abstraction:
Worker:
replicas: 4
template:
spec:
containers:
- image: <aws-account-id>.dkr.ecr.us-west-2.amazonaws.com/neuronx_nemo:latest
name: mpitest
imagePullPolicy: Always
resources:
claims:
- name: neurons
volumeMounts:
- name: dshm
mountPath: /dev/shm
volumes:
- name: dshm
emptyDir:
medium: Memory
resourceClaims:
- name: neurons
resourceClaimTemplateName: efa-neurons-4-devices
The ResourceClaimTemplate name is a given name and can be defined by the ML infra operators to be friendly to their developers. The RCT
definition translates the name into the underlying allocation details - these are abstracted away from ML developers.
Rich interface for resource requests
With DRA, resource requests can specify attribute-based selection. For example, RCT can follow requests, which was not possible to do with device plugins without additional node labeling and extensions. This interface allows us to facilitate topology-aware scheduling.
Allocate connected neuron devices from trn2 instance type and the devices in the set need to be running specified Neuron driver version.
Allocate a specific set of neuron devices for my pod - I want the pod to use devices in row 1 of the topology.
Dynamic configuration
DRA allows end users to specify additional configuration for the device via RCT. The Neuron DRA driver leverages this capability to allow ResourceClaimTemplates to specify LNC size to be used for the allocation. An example is shown below. The end user need not configure LNC via launch template while using Neuron devices with Neuron DRA driver.
#Template will be vended by Neuron via documentation/code repo
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
namespace: neuron-test7
name: lnc-neurons
spec:
spec:
devices:
requests:
- name: neurons
exactly:
deviceClassName: neuron.aws.com
selectors:
- cel:
expression: device.attributes['neuron.aws.com'].instanceType == "trn2.48xlarge"
allocationMode: all
config:
- opaque:
driver: neuron.aws.com
parameters:
apiVersion: neuron.aws.com/v1
kind: NeuronConfig
logicalNeuronCore: 1
requests: ["neurons"]
Prerequisites#
Kubernetes version - Please use K8s control plane 1.34+
Instance type - Trn2.48xlarge launched with K8s version 1.34.2+
For instructions on how to setup an EKS cluster, please refer to prerequisites.
Installation via Helm#
Connect to your cluster from local box. The cluster should have at least one trn2.48xlarge node. Do not install the Neuron device plugin on the cluster!
Please confirm the cluster being used via:
kubectl config current-context
Then install the DRA driver:
helm upgrade --install neuron-helm-chart oci://public.ecr.aws/neuron/neuron-helm-chart \
--set "devicePlugin.enabled=false" --set "npd.enabled=false" --set "draDriver.enabled=true"
Example 1 – Connected Neuron Devices#
This section will demonstrate how to run a workload that needs to request a subset of connected Neuron Devices from a trn2.48xlarge instance. Before DRA, this use case required using Neuron Scheduler Extension. With DRA, this allocation is enabled natively.
The supported subsets include set of 1, 4, 8 or 16. Specifically, these are resource.aws.com/devicegroup1_id, resource.aws.com/devicegroup4_id,
resource.aws.com/devicegroup8_id, resource.aws.com/devicegroup16_id respectively.
The sets of 4 and 8 are selected as shown in diagram below:
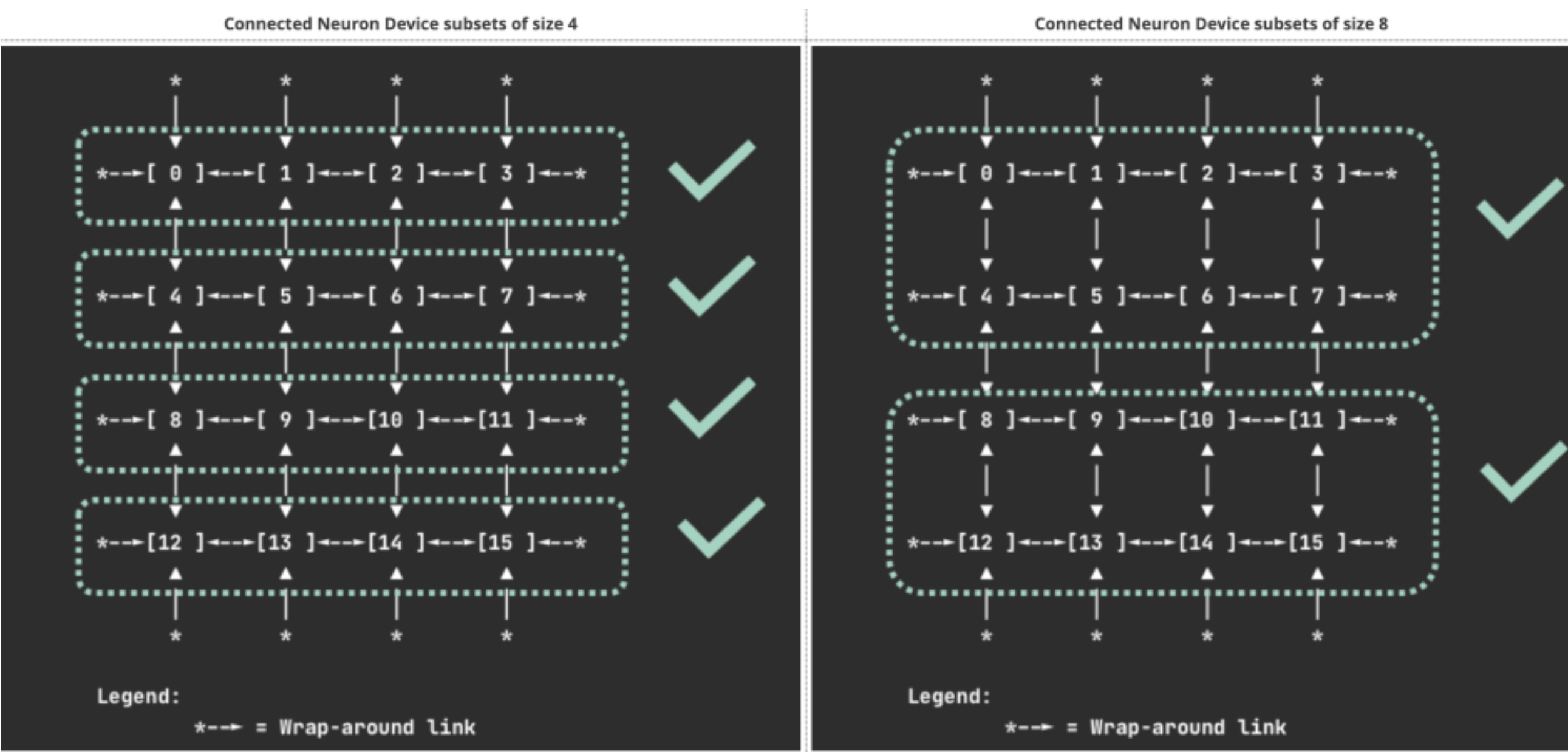
To enable a workload to consume a connected subset of Neuron Devices, first create a ResourceClaimTemplate that requests a connected set of
Neuron devices. From the package run:
kubectl apply -f specs/1x4-connected-devices.yaml
This workload definition (which includes the ResourceClaimTemplate) is shown below for quick reference:
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: 1x4-connected-neurons
spec:
spec:
devices:
requests:
- name: neurons
exactly:
deviceClassName: neuron.aws.com
allocationMode: ExactCount
count: 4
selectors:
- cel:
expression: "device.attributes['neuron.aws.com'].instanceType == 'trn2.48xlarge'"
constraints:
- requests: ["neurons"]
matchAttribute: "resource.aws.com/devicegroup4_id"
Next step is to reference the ResourceClaimTemplate in a pod definition as shown below:
---
apiVersion: v1
kind: Pod
metadata:
name: pod0
labels:
app: pod
spec:
containers:
- name: ctr0
image: public.ecr.aws/ubuntu/ubuntu:22.04
command: ["bash", "-c"]
args: ["export; trap 'exit 0' TERM; sleep 9999 & wait"]
resources:
claims:
- name: neurons
resourceClaims:
- name: neurons
resourceClaimTemplateName: 1x4-connected-neurons
Deploy the above workload using kubectl apply. When the pod is running, examine the related ResourceClaim using:
kubectl get resourceclaim -o yaml
The resourceclaim output will show the 4 Neuron Devices that were allocated to the pod. An example is shown below. These will be connected Neuron
Devices.
[devbox]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
---------------------------------------
pod0 1/1 Running 0 3s
[devbox]$ kubectl get resourceclaim
NAME STATE AGE
---------------------------------------------
pod0-neurons-zdk76 allocated,reserved 9s
[devbox]$ kubectl get resourceclaim pod0-neurons-zdk76 -o yaml
Status shown below:
status:
allocation:
devices:
results:
- adminAccess: null
device: neurondevice2
driver: neuron.aws.com
pool: ip-1-1-1-1.region.compute.internal
request: neurons
- adminAccess: null
device: neurondevice3
driver: neuron.aws.com
pool: ip-1-1-1-1.region.compute.internal
request: neurons
- adminAccess: null
device: neurondevice1
driver: neuron.aws.com
pool: ip-1-1-1-1.region.compute.internal
request: neurons
- adminAccess: null
device: neurondevice0
driver: neuron.aws.com
pool: ip-1-1-1-1.region.compute.internal
request: neurons
Note
The RCT name can be simplified to communicate the intent of the allocation and abstract the allocation details away from ML developers.
Example RCT1 - “xl” - Allocate All 16 devices
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: xl-trn2
spec:
spec:
devices:
requests:
- name: neurons
exactly:
allocationMode: ExactCount
count: 16
deviceClassName: neuron.aws.com
selectors:
- cel:
expression: device.attributes['neuron.aws.com'].instanceType == 'trn2.48xlarge'
Example RCT2 - large - Allocate 8 devices
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: l-trn2
spec:
spec:
devices:
constraints:
- matchAttribute: resource.aws.com/devicegroup8_id
requests:
- neurons
requests:
- name: neurons
exactly:
allocationMode: ExactCount
count: 8
deviceClassName: neuron.aws.com
selectors:
- cel:
expression: device.attributes['neuron.aws.com'].instanceType == 'trn2.48xlarge'
Example RCT2 - 2.27-driver – Allocate 8 devices with driver version at the driver published by Neuron SDK 2.27
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: 2.27-driver-trn2
spec:
spec:
devices:
constraints:
- matchAttribute: resource.aws.com/devicegroup8_id
requests:
- neurons
requests:
- name: neurons
exactly:
allocationMode: ExactCount
count: 8
deviceClassName: neuron.aws.com
selectors:
- cel:
expression: device.attributes['neuron.aws.com'].instanceType == 'trn2.48xlarge' &&
device.attributes['neuron.aws.com'].neuronDriverVersion == '2.25.4.0'
Example 2 - Dynamic LNC config#
This example shows how to set LNC per workload. Earlier, overriding LNC on a Node required a node template. With DRA, workloads can
override default LNC via ResourceClaim.
Apply the following workload definition:
kubectl apply -f specs/lnc-setting-trn2.yaml
This workload definition (which includes the ResourceClaimTemplate) is shown below for quick reference:
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-neurons-lnc-1
spec:
spec:
devices:
requests:
- name: neurons
exactly:
deviceClassName: neuron.aws.com
selectors:
- cel:
expression: "device.attributes['neuron.aws.com'].instanceType == 'trn2.48xlarge'"
allocationMode: All
config:
- requests: ["neurons"]
opaque:
driver: neuron.aws.com
parameters:
apiVersion: neuron.aws.com/v1
kind: NeuronConfig
logicalNeuronCore: 1
Then deploy a pod that references the above ResourceClaimTemplate as shown below:
apiVersion: v1
kind: Pod
metadata:
name: pod0
labels:
app: pod
spec:
containers:
- name: ctr0
image: public.ecr.aws/ubuntu/ubuntu:22.04
command: ["bash", "-c"]
args: ["export; trap 'exit 0' TERM; sleep 9999 & wait"]
resources:
claims:
- name: neurons
resourceClaims:
- name: neurons
resourceClaimTemplateName: all-neurons-lnc-1
Example 3 – Four Node Inference on trn2u.48xlarge#
A trn2u.48xlarge Trn2 UltraServer has 4 Trn2 nodes interconnected by Neuron Links.
trn2u.48xlarge instances can be allocated in set of 1, 2, or 4. The Neuron DRA driver can utilize 1 or more ResourceClaimTemplate definitions to convey the
desired size of the set. The ResourceClaimTemplate allows end users to specify “UltraServerConfig” to declare their intent to use all 4 nodes of
the UltraServer. This configuration value is passed by the Neuron DRA driver to the Neuron runtime and collectives inside the container.
Example yaml for 4-node inference on trn2u.48xlarge:
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: us-4-node-config
spec:
spec:
devices:
requests:
- name: neurons
exactly:
deviceClassName: neuron.aws.com
selectors:
- cel:
expression: "device.attributes['neuron.aws.com'].resourceType == 'neuron_node'"
allocationMode: ExactCount
count: 1
config:
- requests: ["neurons"]
opaque:
driver: neuron.aws.com
parameters:
apiVersion: neuron.aws.com/v1
kind: UltraServerConfig
ultraserverMode: 4
---
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: vllm
annotations:
leaderworkerset.sigs.k8s.io/exclusive-topology: neuron.amazonaws.com/ultraserver-server-id-4
spec:
rolloutStrategy:
type: RollingUpdate
rollingUpdateConfiguration:
maxUnavailable: 1
maxSurge: 1
# Two replica groups of 4 nodes each, i.e. two ultraservers
replicas: 2
leaderWorkerTemplate:
size: 4
restartPolicy: RecreateGroupOnPodRestart
leaderTemplate:
metadata:
labels:
role: leader
spec:
containers:
- name: vllm-leader
image: public.ecr.aws/ubuntu/ubuntu:22.04
command:
- sh
- -c
- "sleep infinity"
resources:
claims:
- name: one-node-from-ultraserver
resourceClaims:
- name: one-node-from-ultraserver
resourceClaimTemplateName: us-4-node-config
workerTemplate:
metadata:
labels:
role: worker
spec:
containers:
- name: vllm-worker
image: public.ecr.aws/ubuntu/ubuntu:22.04
command:
- sh
- -c
- "sleep infinity"
resources:
claims:
- name: one-node-from-ultraserver
resourceClaims:
- name: one-node-from-ultraserver
resourceClaimTemplateName: us-4-node-config
Neuron DRA Driver Attributes Reference#
The Neuron DRA driver publishes the following attributes in resource slices. These attributes can be used in ResourceClaimTemplate CEL expressions
to filter and select specific devices for allocation.
Common Attributes#
These attributes are common to all Neuron instances and their devices:
deviceId- An integer value representing the ID of the Neuron device. Used to identify which device is chosen from allocation.instanceType- A string value representing the EC2 instance type of the Neuron device. Used to specify devices of which instance(s) to choose for allocation.neuronDriverVersion- A string value representing the Neuron driver version running on the instance. Used to claim instances with the same driver version for allocation.draDriverVersion- A version value of the Neuron DRA driver version. Provides visibility on which Neuron DRA driver version published the resource slice.resourceType- A string value to distinguish between devices and UltraServer nodes. For devices, this value isneuron_device. For UltraServers, this value isneuron_node.networkNodeLayer1- A string value representing network node layer 1. Can be used during topology-aware scheduling to minimize network latency and optimize instance placement. See EC2 Instance Topology.networkNodeLayer2- A string value representing network node layer 2. Can be used to allocate workloads to nodes on the same spine. See EC2 Instance Topology.networkNodeLayer3- A string value representing network node layer 3. Can be used during topology-aware scheduling to minimize network latency and optimize instance placement. See EC2 Instance Topology.
Trn Non-UltraServer Attributes#
These attributes are only populated for Neuron instances that have grid topology (trn) and are not UltraServers:
topology_x- An integer value representing the row of the device in a grid topology. Only populated when the number of devices in the instance is greater than 1. Can be used to select a specific device or devices that belong to the same row.topology_y- An integer value representing the column of the device in a grid topology. Only populated when the number of devices in the instance is greater than 1. Can be used to select a specific device or devices that belong to the same column.topology4_id- An integer value representing the row of the device in a grid topology. Only populated when the number of devices in the instance is greater than 1. Can be used to select devices that belong to the same row.topology8_id- An integer value representing the row of the device in a grid topology. Only populated when the number of devices in the instance is greater than or equal to 8. Can be used to select devices that belong to the same two rows.
Trn UltraServer Attributes#
These attributes are only populated for Neuron instances that have grid topology (trn) and are UltraServers:
capacityBlockId- A string value representing the ID of the capacity block that the UltraServer instance is in. See Instance Topology API.
EFA-Enabled Instance Attributes#
These attributes are only populated for Neuron instances that are EFA-enabled:
resource.aws.com/devicegroup1_id- A string value representing the EFA Bus:Device:Function (BDF) corresponding to that device.resource.aws.com/devicegroup4_id- A string value representing a hash, ensuring Neuron devices in the same topology group of 4 get the same group ID.resource.aws.com/devicegroup8_id- A string value representing a hash, ensuring Neuron devices in the same topology group of 8 get the same group ID.resource.aws.com/devicegroup16_id- A string value representing a hash, ensuring Neuron devices in the same topology group of 16 get the same group ID.
FAQs#
Can DRA plugin co-exist with other device plugins?#
Device plugins and the DRA plugin can coexist in the same cluster, but not for the same node. As of now, the two mechanisms act independently. Neuron is preparing an upcoming feature that will allow device plugin based allocations to work with DRA, but the feature is still in alpha and not enabled on EKS. Ref: Extended Resource.
Is DRA replacing Neuron Device Plugin and Scheduler Extension?#
We will continue to support the Neuron Device Plugin and Scheduler Extension as long as:
Upstream Kubernetes continues to support device plugins.
EKS continues to support Kubernetes versions below 1.34 (which do not support DRA).
What Kubernetes versions are supported?#
Kubernetes control plane must be on 1.34. For Node AMI, we support 1.34.2+. We do not support Node AMI for 1.34.0 or 1.34.1 since it had a regression in DRA. Upstream issue: Kubernetes Issue #133920
Where can I learn more about how to put together RCT using CEL expressions?#
To learn more about RCTs, please visit Kubernetes Dynamic Resource Allocation. To learn more about CEL expressions, please visit CEL Language. Send us feedback and let us know which additional RCT examples you would like us to provide in the source code.
This document is relevant for: Trn2, Trn3