
This document is relevant for: Inf1
NeuronCore Pipeline#
The Neuron software feature referred to as a NeuronCore Pipeline refers
to the process of sharding a compute-graph across multiple NeuronCores,
caching the model parameters in each core’s on-chip memory (cache), and
then streaming inference requests across the cores in a pipelined
manner. Based on the number of NeuronCores selected, the model might get
seamlessly sharded across up-to 16 Inferentia devices (i.e. 64
NeuronCores). This enables users to optimize for both throughput and
latency, as it enables the NeuronCores to process neural-networks with
locally cached data and avoid the cost of accessing external memory.
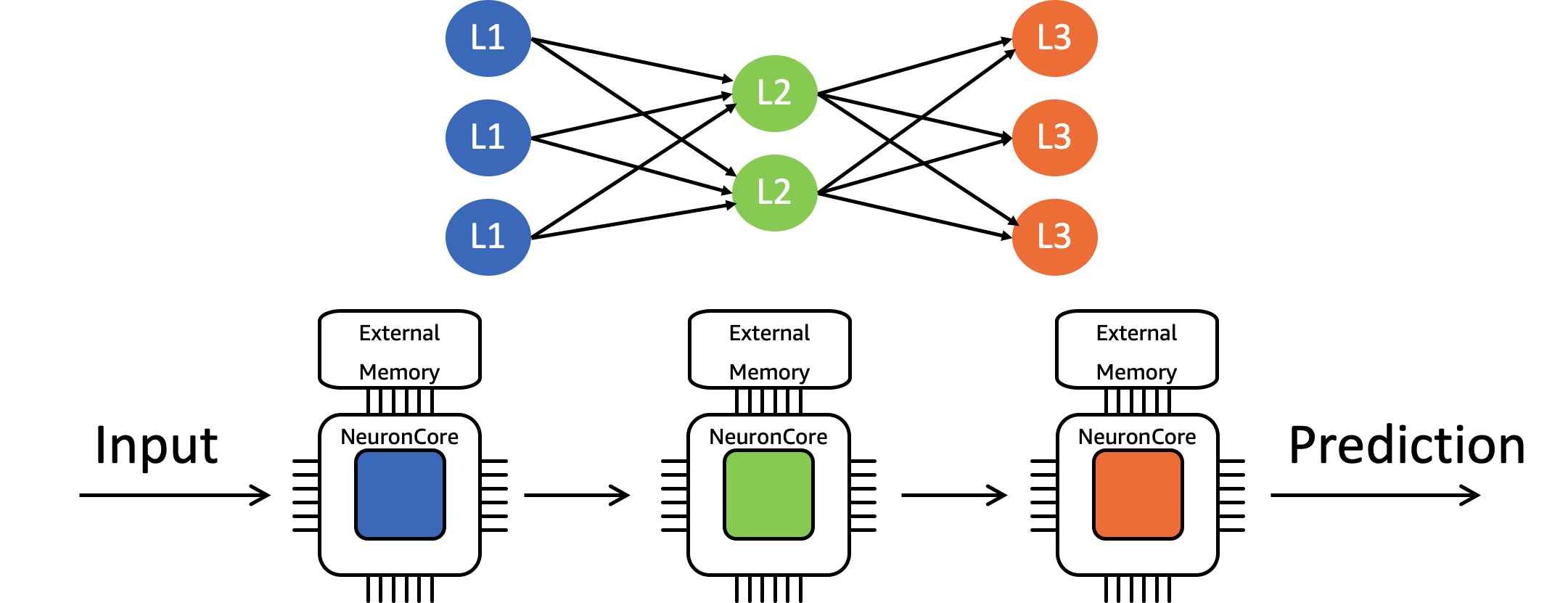
One benefit to this approach is that NeuronCore Pipeline can typically hit maximal hardware efficiency without the need for batching (e.g. BERT, ResNet50).
For maximal performance, users should choose an instance-size that can cache the entire model by using sufficient NeuronCores. Inf1 instance types have different number of Inferentia devices, each of which has 4 NeuronCores, as shown here https://aws.amazon.com/ec2/instance-types/inf1/
To enable the NeuronCore Pipeline optimization, the compiler should be
invoked with the following flags: --neuroncore-pipeline-cores N. The
number of NeuronCores is typically chosen to be the minimal number that
can fit the entire model, which is currently done through a
trial-and-error process (compiling to different number of cores and
looking for compilation success/failure message). This process will be
automated in the future. A simple formula to help define the number of
NeuronCores that may be an appropriate choice is
neuroncore-pipeline-cores = 4 * round( number-of-weights-in-model/(2 * 10^7) )
This allocates a set of NeuronCores based on the size of the given model’s weights and normalizes to multiples of 4 so it uses full Inferentias.
The code snippet below shows how to compile a model with NeuronCore Pipeline for 16 NeuronCores (instance size inf1.6xlarge).
import numpy as np
import tensorflow.neuron as tfn
example_input = np.zeros([1,224,224,3], dtype='float16')
tfn.saved_model.compile("rn50_fp16",
"rn50_fp16_compiled/1",
model_feed_dict={'input_1:0' : example_input },
compiler_args = ['--neuroncore-pipeline-cores', '16'])
This document is relevant for: Inf1