
This document is relevant for: Inf1
Parallel Execution using NEURON_RT_NUM_CORES#
Important
NEURONCORE_GROUP_SIZES will no longer be supported starting with the Neuron 1.19.0 release. If your application uses NEURONCORE_GROUP_SIZES
see Migrate your application to Neuron Runtime 2.x (libnrt.so) and Announcing end of support for NEURONCORE_GROUP_SIZES starting with Neuron 1.20.0 release for more details.
Introduction#
Inf1 instances are available with a different number of Inferentia chips. Each Inferentia chip consists of 4 NeuronCores and an Inf1 instance includes 4 to 64 NeuronCores, depending on the size of the instance. This guide shows you how to load one or more compiled models into different consecutive groups of NeuronCores using your framework of choice.
Data Parallel Execution#
In PyTorch and TensorFlow, the same compiled model can run in parallel on an Inf1 instance by loading it multiple times, up to the total number of NeuronCores specified in NEURON_RT_NUM_CORES or NEURON_RT_VISIBLE_CORES. For more information about NEURON_RT_NUM_CORES and NEURON_RT_VISIBLE_CORES, refer to Neuron Runtime Configuration.
Running multiple models using single process#
To run multiple models using a single process, set the environment
variable NEURON_RT_NUM_CORES with a list of the
number of cores in each group, separated by commas.
You can set the NEURON_RT_NUM_CORES environment variable at runtime:
#!/bin/bash
NEURON_RT_NUM_CORES=13 python your_neuron_application.py
Or from within the Python process running your models (NOTE: You can only set it once in the same process at the beginning of the script):
#!/usr/bin/env python
import os
# Set Environment
os.environ['NEURON_RT_NUM_CORES']='13'
# Load models and run inferences ...
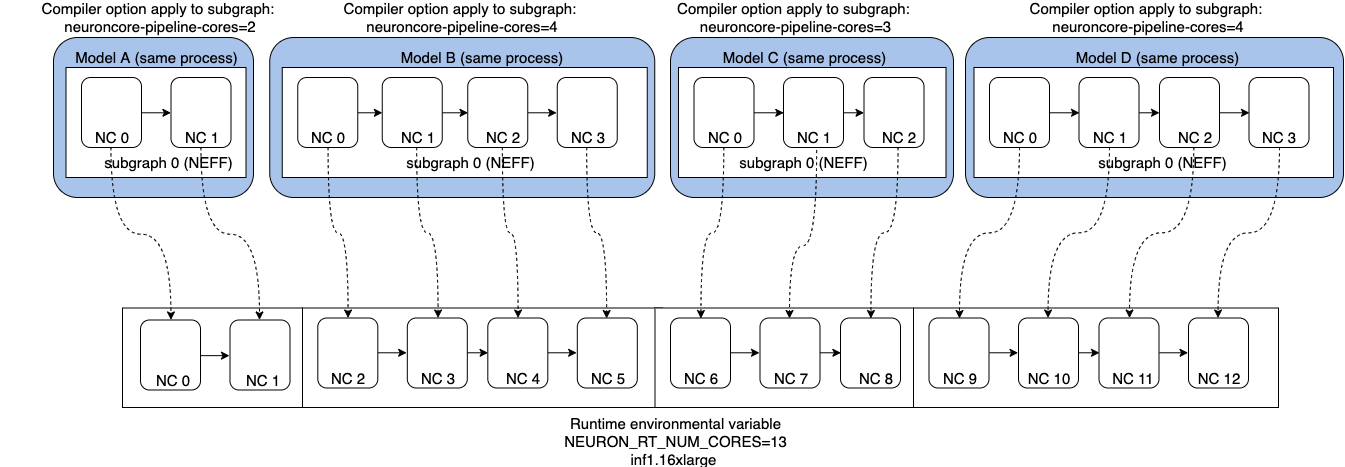
The following examples allow you to load 4 models into 4 groups of NeuronCores within one process. For example, if there are 4 models A, B, C, D compiled to 2, 4, 3, and 4 NeuronCores respectively, directly load the models A, B, C, D in sequence within your TensorFlow or PyTorch Neuron process. This example requires an inf1.6xlarge instance with 16 NeuronCores, as the total number of NeuronCores within the NeuronCore Groups is 13.
In MXNet, mapping from models to NeuronCores is controlled by
context mx.neuron(neuron_core_index) where neuron_core_index is the NeuronCore
index at the start of the group. In the example above, map model A to mx.neuron(0)
context, model B to mx.neuron(2) context, model C to
mx.neuron(6) context and model D to mx.neuron(9) context. For
further details, refer to Flexible Execution Group (FlexEG) in Neuron-MXNet.
For PyTorch
See Data Parallel Inference on Torch Neuron for more details.
For Tensorflow
# Set Environment
os.environ['NEURON_RT_NUM_CORES']='13'
# Load models (TF2)
model0 = tf.keras.models.load_model(model0_file) # loaded into the first group of NC0-NC1
model1 = tf.keras.models.load_model(model1_file) # loaded into the second group of NC2-NC5
model2 = tf.keras.models.load_model(model1_file) # loaded into the third group of NC6-NC8
model3 = tf.keras.models.load_model(model1_file) # loaded into the fourth group of NC9-NC12
# run inference by simply calling the loaded model
results0 = model0(inputs0)
results1 = model1(inputs1)
results2 = model2(inputs2)
results3 = model3(inputs3)
For MXNet 2.x:
# Set Environment
os.environ['NEURON_RT_NUM_CORES']='13'
# Load models (MXNet)
# loaded into the first group of NC0-NC1
sym, args, aux = mx.model.load_checkpoint(mx_model0_file, 0)
model0 = sym.bind(ctx=mx.neuron(0), args=args, aux_states=aux, grad_req='null')
# loaded into the second group of NC2-NC5
sym, args, aux = mx.model.load_checkpoint(mx_model1_file, 0)
model1 = sym.bind(ctx=mx.neuron(2), args=args, aux_states=aux, grad_req='null')
# loaded into the third group of NC6-NC8
sym, args, aux = mx.model.load_checkpoint(mx_model2_file, 0)
model2 = sym.bind(ctx=mx.neuron(6), args=args, aux_states=aux, grad_req='null')
# loaded into the fourth group of NC9-NC12
sym, args, aux = mx.model.load_checkpoint(mx_model3_file, 0)
model3 = sym.bind(ctx=mx.neuron(9), args=args, aux_states=aux, grad_req='null')
# run inference by simply calling the loaded model
results0 = model0.forward(data=inputs0)
results1 = model1.forward(data=inputs1)
results2 = model2.forward(data=inputs2)
results3 = model3.forward(data=inputs3)
You can identify the NeuronCores used by each application with the neuron-top command
line tool. For more information about the neuron-top user interface, see Neuron Top User Guide.
$ neuron-top
Running multiple models using multiple processes#
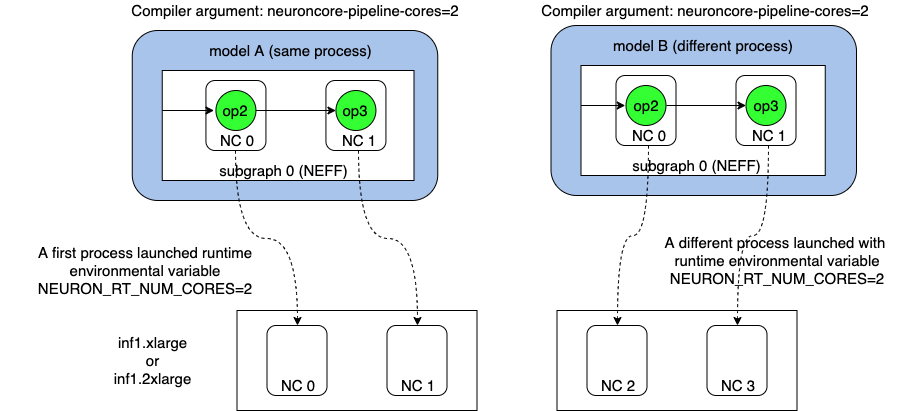
You can also run multiple models in parallel processes, when you set
NEURON_RT_NUM_CORES per process:
$ NEURON_RT_NUM_CORES=2 python your_1st_neuron_application.py
$ NEURON_RT_NUM_CORES=2 python your_2nd_neuron_application.py
The first process automatically selects a first set of 2 unused NeuronCores for its new group. The second process automatically selects a new set of 2 unused NeuronCores for its new group.
Running multiple models on the same NeuronCore group#
You can load more than one model in a NeuronCore group within one process. Neuron runtime handles switching from one model to the next model within the NeuronCore group, when the next model is run within the application. In TensorFlow or PyTorch, simply load the additional models after the initial number of models have been loaded, to fill the NeuronCore groups associated with the process.
For PyTorch:
# Set Environment
os.environ['NEURON_RT_NUM_CORES']='2'
# Load models (PT)
model0 = torch.jit.load(model0_file) # loaded into the first group of NC0-NC1
model1 = torch.jit.load(model1_file) # loaded into the first group of NC0-NC1
# run inference by simply calling the loaded model
results0 = model0(inputs0)
results1 = model1(inputs1)
For TensorFlow 2.x:
# Set Environment
os.environ['NEURON_RT_NUM_CORES']='2'
# Load models (TF2)
model0 = tf.keras.models.load_model(model0_file) # loaded into the first group of NC0-NC1
model1 = tf.keras.models.load_model(model1_file) # loaded into the first group of NC0-NC1
# run inference by simply calling the loaded model
results0 = model0(inputs0)
results1 = model1(inputs1)
In MXNet, use context mx.neuron(neuron_core_index) and use the
same NeuronCore start index for the additional models.
# Set Environment
os.environ['NEURON_RT_NUM_CORES']='2'
# Load models (MXNet)
# loaded into the first group of NC0-NC1
sym, args, aux = mx.model.load_checkpoint(mx_model0_file, 0)
model0 = sym.bind(ctx=mx.neuron(0), args=args, aux_states=aux, grad_req='null')
# loaded into the first group of NC0-NC1
sym, args, aux = mx.model.load_checkpoint(mx_model1_file, 0)
model1 = sym.bind(ctx=mx.neuron(0), args=args, aux_states=aux, grad_req='null')
# run inference by simply calling the loaded model
results0 = model0.forward(data=inputs0)
results1 = model1.forward(data=inputs1)
The total NEURON_RT_NUM_CORES across all processes cannot exceed
the number of NeuronCores available on the instance. For example,
on an inf1.xlarge with default configurations where the total number of
NeuronCores visible to TensorFlow-Neuron is 4, you can launch one
process with NEURON_RT_NUM_CORES=2 (pipelined) and another
process with NEURON_RT_NUM_CORES=2 (data-parallel).
Examples using NEURON_RT_NUM_CORES include:
Auto Model Replication in TensorFlow Neuron (tensorflow-neuron) (Beta)#
Refer to the following API documentation to see how to perform automatic replication on
multiple cores. Note auto-replication will only work on models compiled with pipeline size 1:
via --neuroncore-pipeline-cores=1. If automatic replication is not enabled, the model will default to
replicate on up to 4 cores.
Python API (TF 2.x only):
TensorFlow 2.x (tensorflow-neuron) Auto Multicore Replication (Beta)
CLI API (TF 1.x and TF 2.x):
TensorFlow Neuron 2.x (tensorflow-neuron) Auto Multicore Replication CLI (Beta)
Auto Model Replication (Being Deprecated)#
The Auto Model Replication feature in TensorFlow-Neuron enables you to load the model once and the data parallel replication will occur automatically. This reduces framework memory usage, as the same model is not loaded multiple times. This feature is beta and available in TensorFlow-Neuron only.
To enable Auto Model Replication, set NEURONCORE_GROUP_SIZES to Nx1, where N is the desired replication count (the number of NeuronCore groups, each group has size 1). For example, NEURONCORE_GROUP_SIZES=8x1 would automatically replicate the single-NeuronCore model 8 times.
os.environ['NEURONCORE_GROUP_SIZES'] = '4x1'
or
NEURONCORE_GROUP_SIZES=4x1 python3 application.py
When NEURONCORE_GROUP_SIZES is not set, the default is 4x1, where a single-NeuronCore model is replicated 4 times on any size of inf1 machine.
This feature is only available for models compiled with neuroncore-pipeline-cores set to 1 (default).
You will still need to use threads in the scaffolding code, to feed the loaded replicated model instance, to achieve high throughput.
Example of auto model replication: Running OpenPose on Inferentia
FAQ#
Can I mix data parallel and NeuronCore Pipelines?#
Yes. You can compile the model using the neuroncore-pipeline-cores option. This tells the compiler to set compilation to the specified number of cores for NeuronCore Pipeline. The Neuron Compiler returns a NEFF that fits within this limit. See the Neuron compiler CLI Reference Guide (neuron-cc) for instructions on how to use this option.
For example, on an inf1.2xlarge, you can load two model instances, each compiled with neuroncore-pipeline-cores set to 2, so they can run in parallel. The model instances can be loaded from different saved models or from the same saved model.
Can I have a mix of multiple models in one Neuroncore group and single model in another one Neuroncore group?#
Currently, you can do this in MXNet, by setting up two Neuroncore groups, then loading, for example, multiple models in one NCG, using context mx.neuron(0), and loading a single model in the second NCG, using context mx.neuron(2). You can also load a single model in the first NCG and multiple models in the second NCG. For example:
# Set Environment
os.environ['NEURON_RT_NUM_CORES']='6'
# Load models (MXNet)
# loaded into the first group of NC0-NC1
sym, args, aux = mx.model.load_checkpoint(mx_model0_file, 0)
model0 = sym.bind(ctx=mx.neuron(0), args=args, aux_states=aux, grad_req='null')
# loaded into the second group of NC2-NC5
sym, args, aux = mx.model.load_checkpoint(mx_model1_file, 0)
model1 = sym.bind(ctx=mx.neuron(2), args=args, aux_states=aux, grad_req='null')
# loaded into the second group of NC2-NC5
sym, args, aux = mx.model.load_checkpoint(mx_model2_file, 0)
model2 = sym.bind(ctx=mx.neuron(2), args=args, aux_states=aux, grad_req='null')
# loaded into the second group of NC2-NC5
sym, args, aux = mx.model.load_checkpoint(mx_model3_file, 0)
model3 = sym.bind(ctx=mx.neuron(2), args=args, aux_states=aux, grad_req='null')
# run inference by simply calling the loaded model
results0 = model0.forward(data=inputs0)
results1 = model1.forward(data=inputs1)
results2 = model2.forward(data=inputs2)
results3 = model3.forward(data=inputs3)
Loading multiple models in one NCG and a single model in another NCG is currently not supported in TensorFlow and PyTorch.
This document is relevant for: Inf1