
This document is relevant for: Inf2
Inferentia2 Architecture#
At the heart of each Inf2 instance are up to twelve Inferentia2 chips (each with two NeuronCore-v2 cores). Inferentia2 is the second generation AWS purpose-built Machine Learning inference accelerator. The Inferentia2 chip architecture is depicted below:
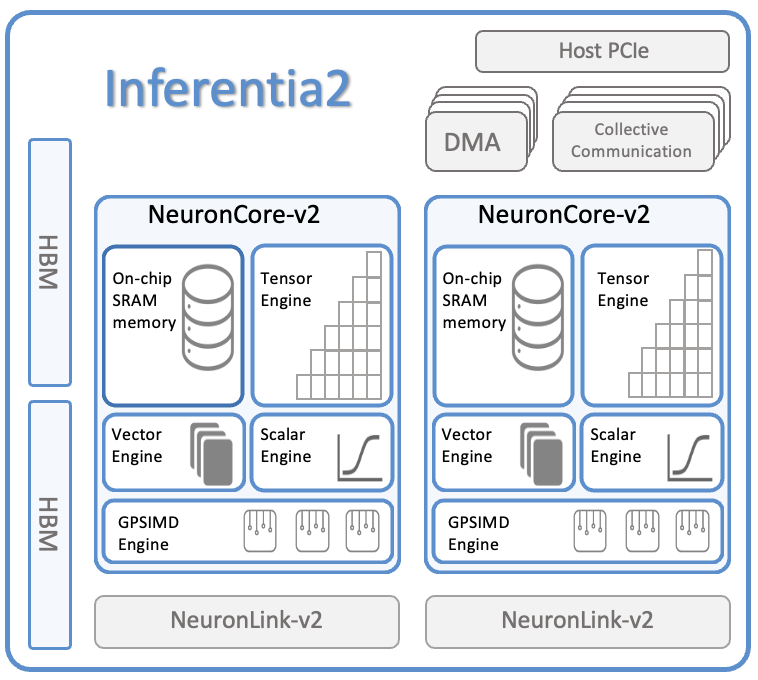
Each Inferentia2 chip consists of:
Compute |
Two NeuronCore-v2 cores, delivering 380 INT8 TOPS, 190 FP16/BF16/cFP8/TF32 TFLOPS, and 47.5 FP32 TFLOPS. |
Device Memory |
32GiB of high-bandwidth device memor (HBM) (for storing model state), with 820 GiB/sec of bandwidth. |
Data Movement |
1 TB/sec of DMA bandwidth, with inline memory compression/decompression. |
NeuronLink |
NeuronLink-v2 for chip-to-chip interconnect enables high-performance collective compute for co-optimization of latency and throughput. |
Programmability |
Inferentia2 supports dynamic shapes and control flow, via ISA extensions of NeuronCore-v2 and custom-operators via the deeply embedded GPSIMD engines. |
For a more detailed description of all the hardware engines, see NeuronCore-v2.
This document is relevant for: Inf2