
This document is relevant for: Trn3
Amazon EC2 Trn3 Architecture#
Amazon EC2 Trn3 instances are accelerated computing instances powered by Trainium3 AI chips, purpose-built for high-performance deep learning training and inference. Trn3 is available in two UltraServer scale-up configurations: Gen1 with 64 Trainium3 chips per UltraServer, and Gen2 with 144 chips per UltraServer. Both configurations use NeuronSwitch-v1 interconnect technology to enable all-to-all connectivity between chips, especially optimized for workloads that leverage all-to-all communication patterns, such as Mixture of Experts models and autoregressive inference serving.
Trn3 Gen1 UltraServer#
The EC2 Trn3 Gen1 UltraServers deliver 161 PetaFLOPS of dense MXFP8 compute, 314 TB/s of HBM bandwidth, and 9TB of HBM capacity. Each UltraServer consists of four servers with 16 Trainium3 devices per server. Therefore, the UltraServer integrates a total of 64 Trainium3 devices into a single scale-up domain, interconnected via our latest-generation NeuronLink-v4 and the newly introduced NeuronSwitch-v1. The chip-to-chip topology features an all-to-all connectivity design, replacing the previous 2D-torus architecture. This all-to-all topology is optimized for workloads that require efficient all-to-all communication patterns or ultra-low latency collectives, including Mixture of Experts models and autoregressive inference serving. The following diagram illustrates the Trn3 Gen1 UltraServer connectivity.
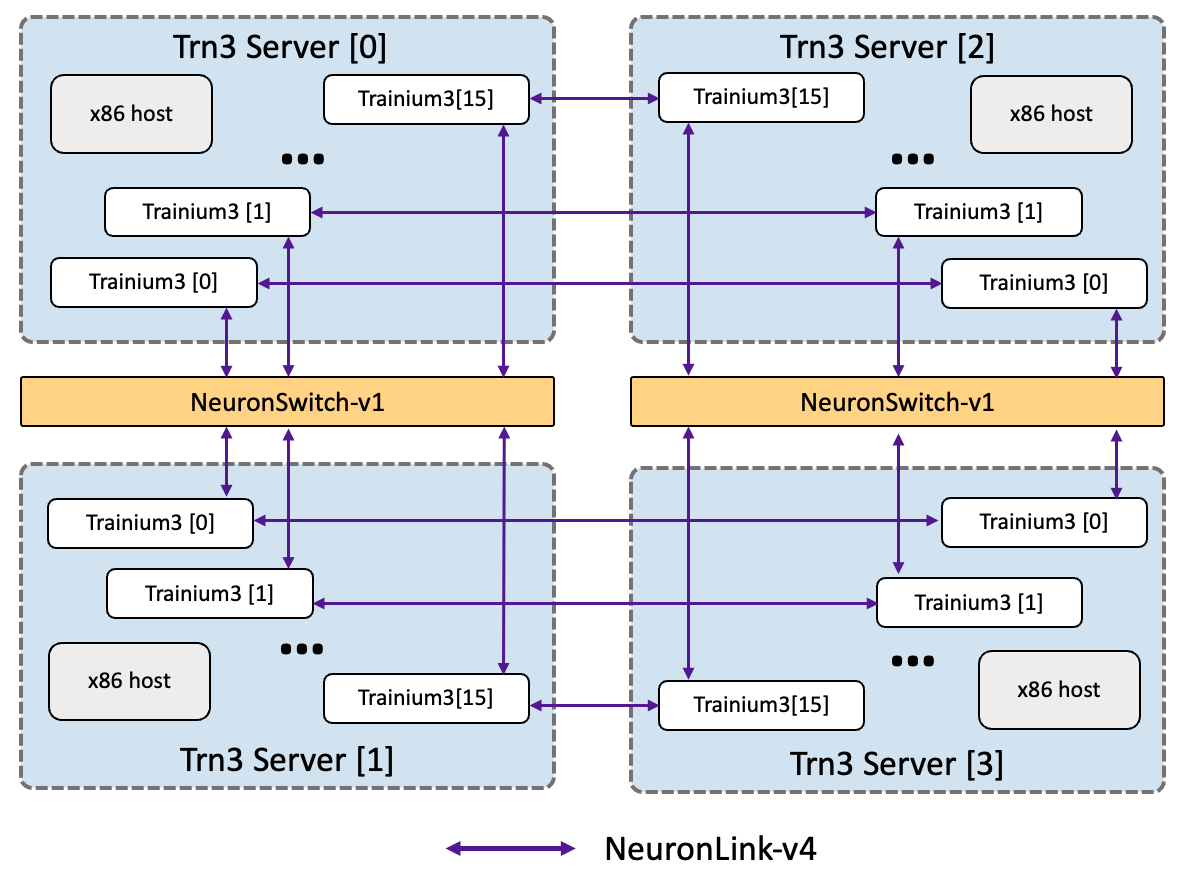
Trn3 Gen2 UltraServer#
The EC2 Trn3 Gen2 UltraServers deliver 362 PetaFLOPS of dense MXFP8 compute, 706 TB/s of HBM bandwidth, and 20TB of HBM capacity. Each UltraServer consists of 36 servers with 4 Trainium3 devices per server. Trainium3 devices within the same server are connected via a first-level NeuronSwitch-v1, while devices across servers are connected via two second-level NeuronSwitch-v1 and NeuronLink-v4. Therefore, the UltraServer integrates 144 Trainium3 devices into a single scale-up domain. Like Gen1, the chip-to-chip topology features an all-to-all connectivity design optimized for Mixture of Experts models and autoregressive inference serving. The following diagram illustrates the Trn3 Gen2 UltraServer connectivity.
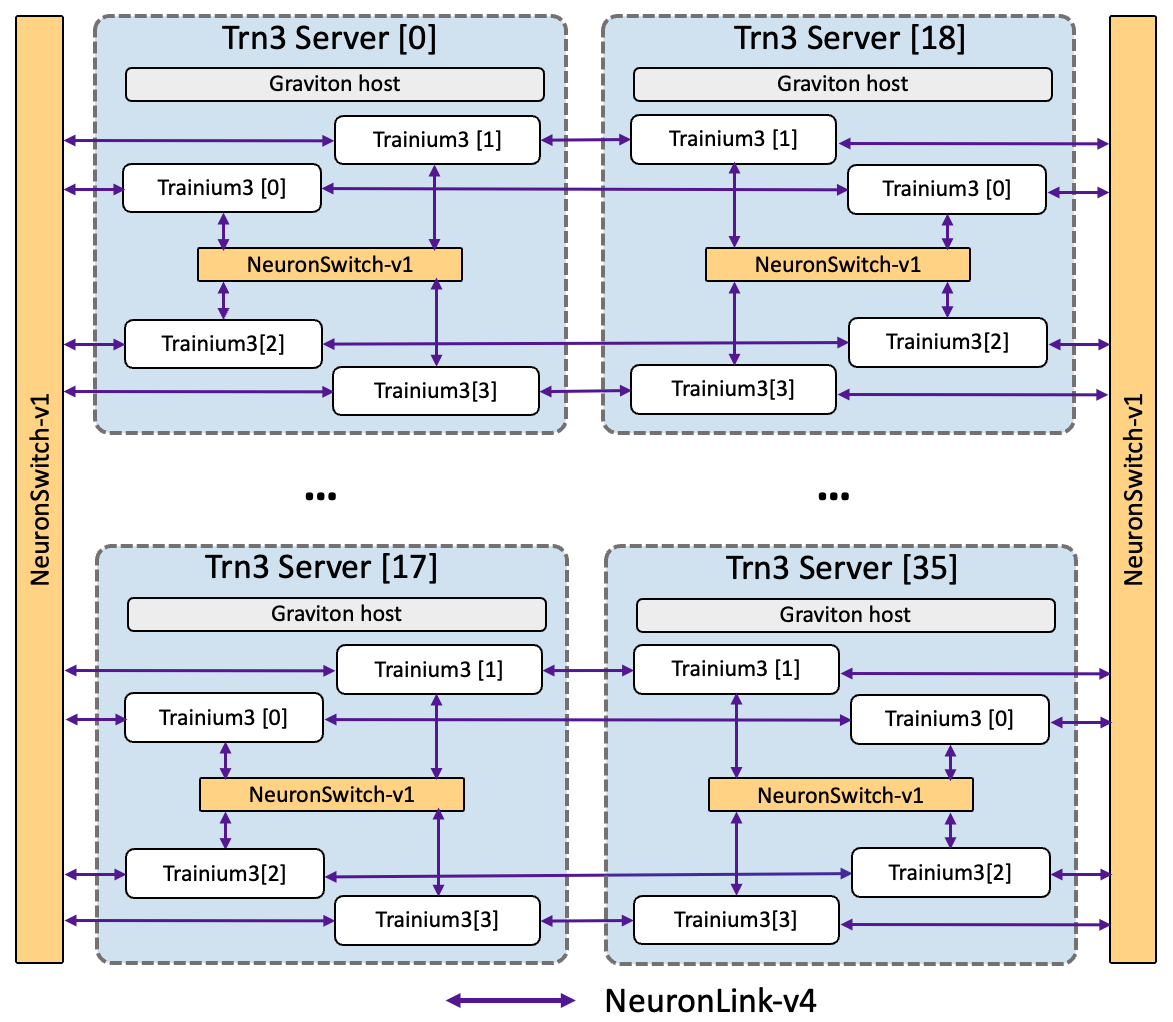
Trn3 Gen1/Gen2 UltraServer specifications#
The following table shows the performance metrics for Tranium3 based instances.
Trn3 Gen1 UltraServer |
Trn3 Gen2 UltraServer |
|
|---|---|---|
Configuration |
||
# of Trainium3 devices |
64 |
144 |
Host vCPUs |
768 |
2304 |
Host Memory (GiB) |
8,192 |
27,648 |
Compute |
||
MXFP8/MXFP4 TFLOPS |
161,088 |
362,448 |
FP16/BF16/TF32 TFLOPS |
42,944 |
96,624 |
FP32 TFLOPS |
11,712 |
26,352 |
Memory |
||
Device Memory (GiB) |
9,216 |
20,736 |
Device Memory Bandwidth (TB/sec) |
313.6 |
705.6 |
Interconnect |
||
NeuronLink-v4 bandwidth (GiB/sec/device) |
2,048 |
2,048 |
EFA bandwidth (Gbps) |
12,800 |
28,800 |
Trn3 UltraServer Connectivity and Networking#
Trn3 UltraServers use a PCIe switch-based interconnect architecture for all chip-to-chip communication, both within and across servers. This replaces the point-to-point NeuronLink topology used in previous generations (Trn1, Trn2) with a switched fabric that enables flexible, all-to-all connectivity across the entire UltraServer domain.
Intra-server connectivity#
Each server (sled) contains 4 Trainium3 chips connected through an intra-server PCIe switch. Each chip provides four PCIe Gen6 x8 links to this switch, delivering a total of 256 GB/s of bidirectional bandwidth between chips within the same server. This local switch enables low-latency communication for operations like tensor parallelism and data-parallel gradient synchronization within a server.
Inter-server connectivity#
All servers within a rack are connected through inter-server PCIe switches. Each Trainium3 chip provides five PCIe Gen6 x8 links to the inter-server switch, delivering 320 GB/s of bidirectional bandwidth per chip for cross-server communication. This enables collective operations such as all-reduce and all-gather to span all servers in a rack without requiring host CPU involvement.
Inter-rack connectivity#
For multi-rack configurations, Trainium3 chips in corresponding positions across racks are connected via dedicated direct PCIe links. Each chip provides two PCIe Gen6 x8 links for inter-rack communication, delivering 128 GB/s of bidirectional bandwidth per chip between racks. This direct-link design avoids additional switch hops for cross-rack traffic.
Bandwidth summary#
Connectivity level |
Bandwidth per chip |
Link configuration |
|---|---|---|
Intra-server (within sled) |
256 GB/s |
4 × PCIe Gen6 x8 via intra-server switch |
Inter-server (within rack) |
320 GB/s |
5 × PCIe Gen6 x8 via inter-server switch |
Inter-rack |
128 GB/s |
2 × PCIe Gen6 x8 direct links |
Routing and address-based switching#
Unlike Trn1 and Trn2, where NeuronLink connections are point-to-point and require no intermediate routing, Trn3’s PCIe switch fabric uses address-based routing to direct transactions to the correct destination chip. Each Trainium3 chip in the system is identified by a tuple of (rack, server, chip), and this identity is encoded in the upper bits of the PCIe address used for outbound transactions. The PCIe switches use BAR (Base Address Register) address matching to determine the correct output port for each transaction.
This routing is transparent to ML workloads. The Neuron Runtime and compiler handle all address encoding and switch configuration automatically. From the developer’s perspective, collective operations and direct memory access between chips work the same way as on previous Trainium generations.
Semaphore-based synchronization#
Trn3 uses hardware semaphores to synchronize data transfers across the switched fabric. When a chip writes data to a remote chip’s HBM, a follow-up semaphore write signals completion to the receiving chip. The system guarantees that data and its associated semaphore always traverse the same physical path through the switch fabric, ensuring correct ordering without additional software synchronization overhead.
This document is relevant for: Trn3