
This document is relevant for: Trn3
NeuronCore-v4 Architecture#
NeuronCore-v4 is the fourth-generation NeuronCore that powers Trainium3 chips. It is a fully-independent heterogenous compute unit consisting of 4 main engines: Tensor, Vector, Scalar, and GPSIMD, with on-chip software-managed SRAM memory to maximize data locality and optimize data prefetch.
The following diagram shows a high-level overview of the NeuronCore-v4 architecture.
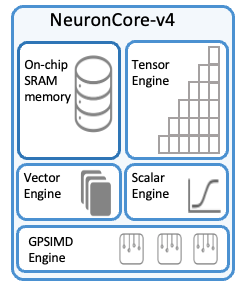
Like previous generations of NeuronCore, NeuronCore-v4 supports control flow, dynamic shapes, and programmable rounding mode (RNE & Stochastic-rounding). NeuronCore-v4 is made up of the following components:
On-chip SRAM#
Each NeuronCore-v4 has a total of 32MiB of on-chip SRAM. The on-chip SRAM is software-managed to maximize data locality and optimize data prefetch. NeuronCore-v4 SRAM also introduces a new near-memory accumulation feature, which allows DMA engines to perform a read-add-write operation into existing SRAM data via a single transfer.
Tensor Engine#
Tensor engines are based on a power-optimized systolic array. They are highly optimized for tensor computations such as GEMM, CONV, and Transpose. Tensor Engines support mixed-precision computations, including MXFP8/MXFP4, FP16, BF16, TF32, and FP32 inputs. The output data type can either be FP32 or BF16. A NeuronCore-v4 Tensor Engine delivers 315 MXFP8/MXFP4 TFLOPS, where MXFP8/MXFP4 are OCP (Open Compute Project) compliant data type formats. MXFP4 data types are converted to MXFP8 before Tensor Engine computation logic, using any arbitrary programmer-defined mapping. Besides quantized data types, a NeuronCore-v4 Tensor Engine also delivers 79 BF16/FP16/TF32 and 20 FP32 TFLOPS of tensor computations.
The NeuronCore-v4 Tensor Engine also supports Structured Sparsity, delivering up to 315 TFLOPS of FP16/BF16/TF32 compute. This is useful when one of the input tensors to matrix multiplication exhibits a M:N sparsity pattern, where only M elements out of every N contiguous elements are non-zero. NeuronCore-v4 supports several sparsity patterns, including 4:16, 4:12, 4:8, 2:8, 2:4, 1:4, and 1:2.
Vector Engine#
Optimized for vector computations, in which every element of the output is dependent on multiple input elements. Examples include axpi operations (Z=aX+Y), Layer Normalization, and Pooling operations.
Vector Engines are highly parallelized, and deliver a total of 1.2 TFLOPS of FP32 computations. NeuronCore-v3 Vector Engines can handle various data-types, including FP8, FP16, BF16, TF32, FP32, INT8, INT16, and INT32.
In addition, NeuronCore-v4 Vector Engine supports two new features:
Data quantization into MXFP8 data type formats from BF16/FP16, which is particularly useful for online data quantization in between MLP (multi-layer perceptron) layers.
Fast exponential functional evaluation, at 4x higher throughput than exponential on Scalar Engine, which is particularly useful in self attention acceleration.
Scalar Engine#
Optimized for scalar computations in which every element of the output is dependent on one element of the input. Scalar Engines are highly parallelized, and deliver a total of 1.2 TFLOPS of FP32 computations. NeuronCore-v3 Scalar Engines support multiple data types, including FP8, FP16, BF16, TF32, FP32, INT8, INT16, and INT32.
GPSIMD Engine#
Each GPSIMD engine consists of eight fully-programmable 512-bit wide vector processors. They can execute general purpose C/C++ code and access the embedded on-chip SRAM, allowing you to implement custom operators and execute them directly on the NeuronCores.
This document is relevant for: Trn3