
This document is relevant for: Trn3
Trainium3 Architecture#
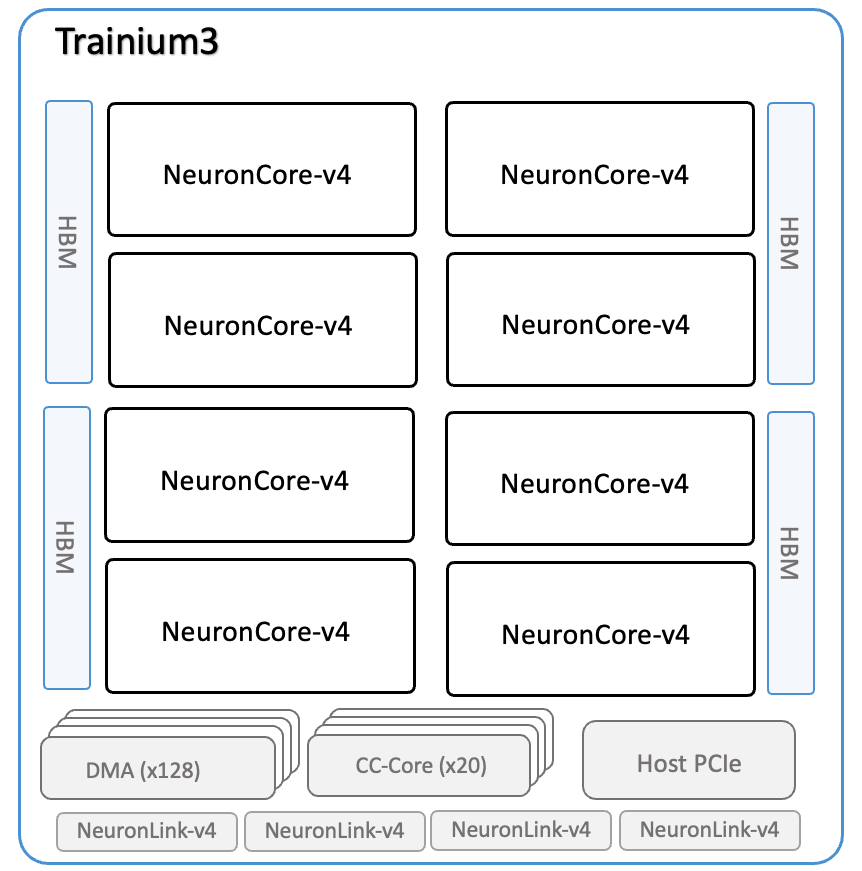
Trainium3 is the fourth-generation purpose-built Machine Learning chip from AWS. A Trainium3 device contains eight NeuronCore-v4 cores. Similar to Trainium2, AWS Neuron adds support for Logical NeuronCore Configuration (LNC), which lets you combine the compute and memory resources of multiple physical NeuronCores into a single logical NeuronCore. The following diagram shows the architecture overview of a Trainium3 chip.
NeuronCore-v4#
Each Trainium3 chip consists of the following components:
Compute |
Eight NeuronCore-v4 cores that collectively deliver:
|
|---|---|
Device memory |
144 GiB of device memory, with 4.9 TB/sec of bandwidth. |
Data movement |
4.9 TB/sec of DMA bandwidth, with inline computation. |
NeuronLink |
NeuronLink-v4 for device-to-device interconnect provides 2.56 TB/sec bandwidth per device. It enables efficient scale-out training, as well as memory pooling between the different Trainium3 devices. |
Programmability |
Trainium3 supports dynamic shapes and control flow, via ISA extensions of NeuronCore-v4. Trainium3 also allows for user-programmable rounding mode (Round Nearest Even or Stochastic Rounding), and custom operators via the deeply embedded GPSIMD engines. |
Collective communication |
16 CC-Cores orchestrate collective communication among Trainium3 devices, both within a server and across servers. |
Trainium3 performance improvements#
The following set of tables offer a comparison between Trainium2 and Trainium3 chips.
Compute#
Trainium2 |
Trainium3 |
Improvement factor |
|
|---|---|---|---|
MXFP4 (TFLOPS) |
Not applicable |
2517 |
|
FP8 (TFLOPS) |
1299 |
2517 |
2x |
BF16/FP16/TF32 (TFLOPS) |
667 |
671 |
1x |
FP32 (TFLOPS) |
181 |
183 |
1x |
Memory#
Trainium2 |
Trainium3 |
Improvement factor |
|
|---|---|---|---|
HBM Capacity (GiB) |
96 |
144 |
1.5x |
HBM Bandwidth (TB/sec) |
2.9 |
4.9 |
1.7x |
SBUF Capacity (MiB) |
224 |
256 |
1.14x |
Interconnect#
Trainium2 |
Trainium3 |
Improvement factor |
|
|---|---|---|---|
Inter-chip Interconnect (GB/sec/chip) |
1280 |
2560 |
2x |
Data movement#
Trainium2 |
Trainium3 |
Improvement factor |
|
|---|---|---|---|
DMA Bandwidth (TB/sec) |
3.5 |
4.9 |
1.4x |
Additional resources#
For a detailed description of NeuronCore-v4 hardware engines, instances powered by AWS Trainium3, and Logical NeuronCore configuration, see the following resources:
This document is relevant for: Trn3