
This document is relevant for: Inf1
Flexible Execution Group (FlexEG) in Neuron-MXNet#
Introduction#
Inf1 instances are available with a different number of Inferentia chips, each Inferentia chip is combined of 4 NeuronCores and an Inf1 instance includes 4 to 64 NeuronCores depending on the instance size. With Neuron Runtime 1.x (neuron-rtd server), NeuronCores could be combined into NeuronCore Groups (NCG), which were basic scheduling units of compiled neural network in Neuron. Creation of desired sized NCGs was done at the start of the application and could not be modified afterwards.
Starting with Neuron SDK 1.16.0, and with the introduction of Neuron Runtime 2.x, MXNet Neuron 1.8 introduces Flexible Execution Groups (FlexEG) feature. With FlexEG, you do not have to create NCGs at the start of the process, instead you will set the index of the first NeuronCore you want to load models onto, and FlexEG feature will enable the flexibility of loading models onto any available NeuronCore on the inf1 instance starting from the first NeuronCore you set. This guide will show you how to efficiently utilize NeuronCores using FlexEG feature in NeuronMXNet.
FlexEG#
With the introduction of FlexEG, you don’t need to create NCGs and can load models onto a group of consecutive NeuronCores by providing the index of the first NeuronCore in the group. Neuron runtime takes care of figuring out the number of NeuronCores required for the given compiled model and loads the model using the required number of cores (sequentially starting with the NeuronCore index provided by the user).
For example, assuming that you have an Inf1.6xl machine and there are 4
models A, B, C, D compiled to 2, 4, 3, and 4 NeuronCores respectively,
you can map any model to any core by context
mx.neuron(neuron_core_index) where neuron_core_index is the
NeuronCore index (0,1,2,3,4 … ).
In the example below, you map model A to mx.neuron(0) context, model
B to mx.neuron(2) context, model C to mx.neuron(6) context and
model D to mx.neuron(9) context.
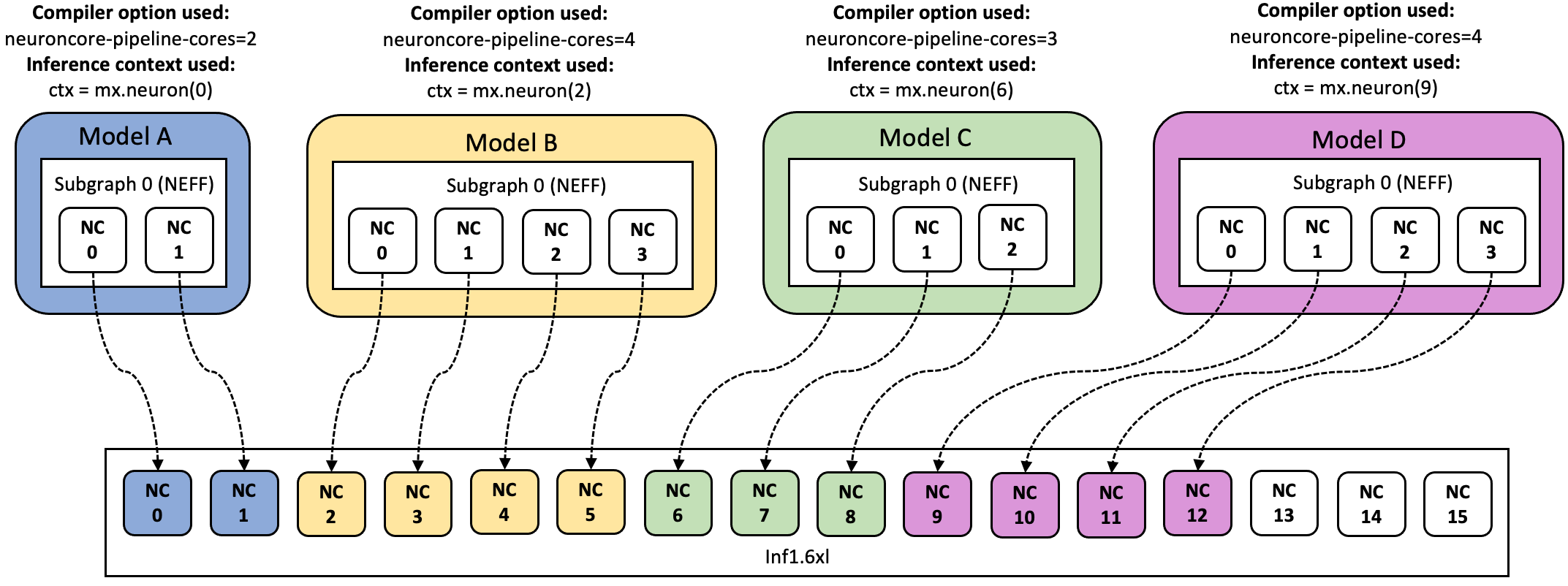
The above configuration is achieved by using application code similar to below:
# Load models (MXNet)
# loaded into the 2 cores starting with core 0
sym, args, aux = mx.model.load_checkpoint(mx_model0_file, 0)
model0 = sym.bind(ctx=mx.neuron(0), args=args, aux_states=aux, grad_req='null')
# loaded into the 4 cores starting with core 2
sym, args, aux = mx.model.load_checkpoint(mx_model1_file, 0)
model1 = sym.bind(ctx=mx.neuron(2), args=args, aux_states=aux, grad_req='null')
# loaded into the 3 cores starting with core 6
sym, args, aux = mx.model.load_checkpoint(mx_model2_file, 0)
model2 = sym.bind(ctx=mx.neuron(6), args=args, aux_states=aux, grad_req='null')
# loaded into the 4 cores starting with core 9
sym, args, aux = mx.model.load_checkpoint(mx_model3_file, 0)
model3 = sym.bind(ctx=mx.neuron(9), args=args, aux_states=aux, grad_req='null')
# run inference by simply calling the loaded model
results0 = model0.forward(data=inputs0)
results1 = model1.forward(data=inputs1)
results2 = model2.forward(data=inputs2)
results3 = model3.forward(data=inputs3)
Since there is no NCG creation at the start of the process, you can load
the same four models but in a different configuration by changing the
context being used for inference. For example, you could map model C to
mx.neuron(0) context, model A to mx.neuron(3) context, model D
to mx.neuron(5) context and model B to mx.neuron(9) context.
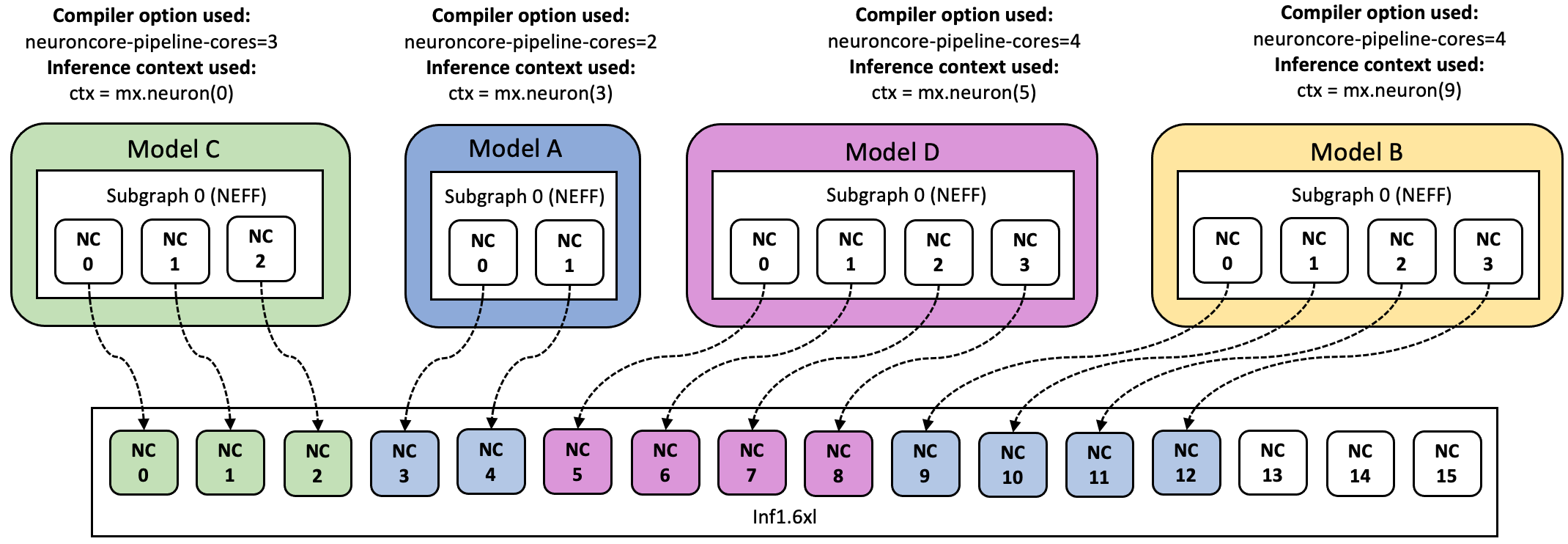
Migration from NeuronCore Groups to FlexEG#
NeuronCore Groups are defined by setting the environment variable
NEURONCORE_GROUP_SIZES with a comma separated list of number of
cores in each group. In this mode of operation, number of devices
(defined in NEURONCORE_GROUP_SIZES) are grouped together to create a
single entity.
NEURONCORE_GROUP_SIZES environment variable is set at runtime:
#!/bin/bash
export NEURONCORE_GROUP_SIZES=2,4,3,4
python your_neuron_application.py
NeuronCore groups are created once at the start of the application and
cannot be modified / re-created till the application process runs. The
above flow creates 4 neuron devices with 2,4,3 and 4 devices each. In
order to get the same configuration as the example from before , you map
model A to mx.neuron(0) context, model B to mx.neuron(1)
context, model C to mx.neuron(2) context and model D to
mx.neuron(3) context.
This can be achieved programmatically as shown below:
# Set Environment
os.environ['NEURONCORE_GROUP_SIZES']='2,4,3,4'
# Load models (MXNet)
# loaded into the first group of NC0-NC1
sym, args, aux = mx.model.load_checkpoint(mx_model0_file, 0)
model0 = sym.bind(ctx=mx.neuron(0), args=args, aux_states=aux, grad_req='null')
# loaded into the second group of NC2-NC5
sym, args, aux = mx.model.load_checkpoint(mx_model1_file, 0)
model1 = sym.bind(ctx=mx.neuron(1), args=args, aux_states=aux, grad_req='null')
# loaded into the third group of NC6-NC8
sym, args, aux = mx.model.load_checkpoint(mx_model2_file, 0)
model2 = sym.bind(ctx=mx.neuron(2), args=args, aux_states=aux, grad_req='null')
# loaded into the fourth group of NC9-NC12
sym, args, aux = mx.model.load_checkpoint(mx_model3_file, 0)
model3 = sym.bind(ctx=mx.neuron(3), args=args, aux_states=aux, grad_req='null')
# run inference by simply calling the loaded model
results0 = model0.forward(data=inputs0)
results1 = model1.forward(data=inputs1)
results2 = model2.forward(data=inputs2)
results3 = model3.forward(data=inputs3)
So comparing to FlexEG, we see that in case of NCGs neuron context
requires the index of the execution group, while in FlexEG
neuron context requires the NeuronCore index of the first NeuronCore on which the
model is supposed to be loaded and executed. For example, with
NEURONCORE_GROUP_SIZES='2,4,3,4', ctx=mx.neuron(1) loads the
model on execution group 1 which effectively loads the model on the 2nd NCG group
which has 4 NeuronCores.
Best practices when using FlexEG#
FlexEG gives the user most flexibility in terms of accessing cores and loading models on specific cores. With this the users can effortlessly load and execute new models on NeuronCores without closing the application. Here we shall outline some of the best practices that should be kept in mind while using FlexEG.
Choosing starting core#
FlexEG tries to use the required number of cores (based on the input model) starting with the core index provided by the user. Incase the system, doesnt have the required number of cores after the starting core index, model load will fail. For example: We have a model X which needs 2 cores and an inf1.xl machine with 4 NeuronCores (NeuronCore indexes are: 0, 1, 2 and 3). As the model needs at least 2 cores, valid start indexes for this model are: 0, 1, 2. However if the user gives 3 as the neuron context, then there are no 2 cores available starting from core 3. So it will fail.
Performance vs. Flexibility tradeoff#
While using data parallel model of operation (were models are executed
in parallel), for optimal performance the user should make sure that the
models are not sharing any cores. That is because NeuronCores can
execute one model at a time, when two or more models are executed on the
same core (assuming that they are already loaded), it executes the first model, stops it, starts the second
model and then executes it. This is called model switiching and involves
additional overhead and prevents execution on model in parallel. For
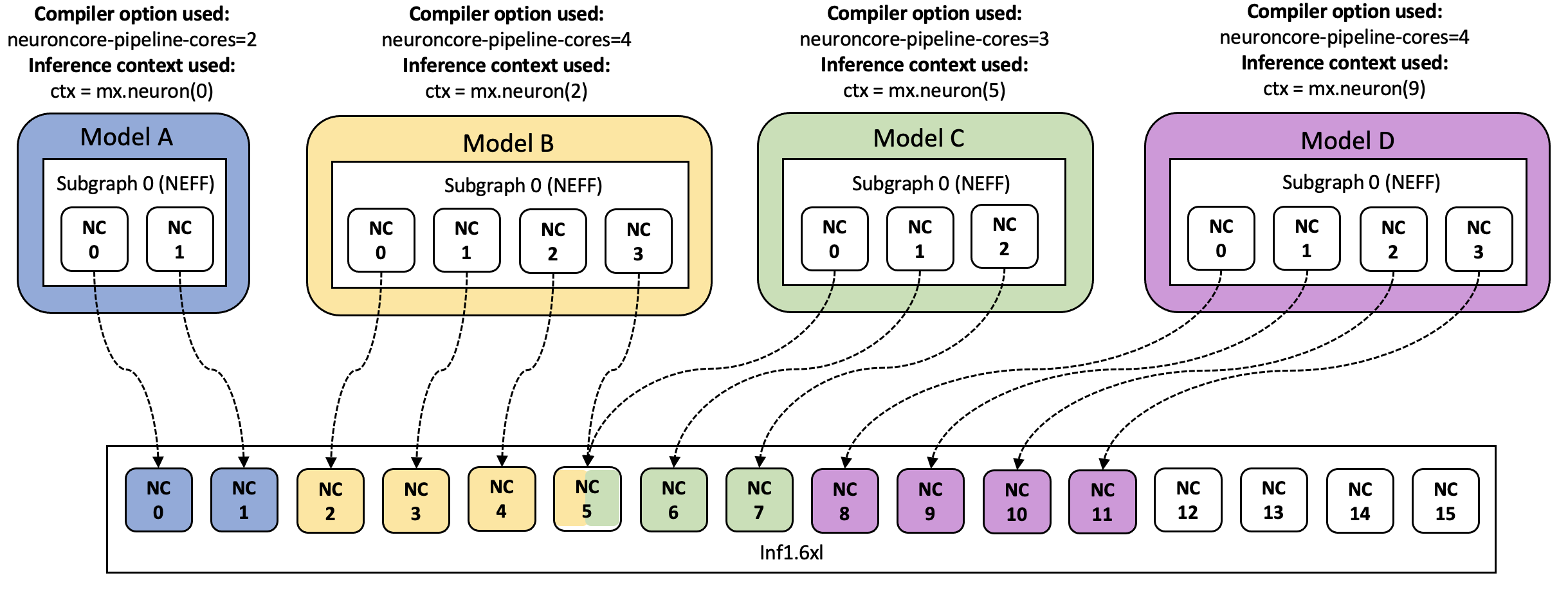
example: assuming that you have an Inf1.6xl machine and there are 4
models A, B, C, D compiled to 2, 4, 3, and 4 NeuronCores respectively.
Loading model A to mx.neuron(0) context, model B to mx.neuron(2)
context, model C to mx.neuron(6) context and model D to
mx.neuron(9) context is a good configuration because no two models
are sharing NeuronCores and thus can be executed in parallel. However,
Loading model A to mx.neuron(0) context, model B to mx.neuron(2)
context, model C to mx.neuron(5) context and model D to
mx.neuron(9) context is a not a good configuration as models B and C
share NeuronCore 5 and thus cannot be executed in parallel.
This document is relevant for: Inf1