
This document is relevant for: Inf1, Inf2, Trn1, Trn2
Compute-Communication Overlap in Neuron#
Background#
Collective communication (CC) operations on the AWS Trainium System-on-Chip (SoC) architecture are executed autonomously from computation engines using dedicated CC cores. Computation engines on each Neuron core do not execute explicit communication instructions. Instead, they asynchronously initiate the CC core and later retrieve completion signals once CC operations finish. The Neuron compiler implements this mechanism by generating pseudo-instructions (PseudoTriggerCollective2 or PTC2) for each CC operation in the engine binaries of the Neuron Executable File Format (NEFF).
When a NEFF is loaded, the Neuron Runtime translates these pseudo-instructions into Write instructions to trigger the CC core during execution. At the same time, the runtime loads the collective communication program for the control path and pre-constructed DMA rings that establish the data path for CC operations. During runtime execution, whenever a Neuron core triggers a CC core, the next scheduled operation advances through the configured DMA rings, enabling inter-core data transfer using a semaphore-based synchronization protocol among CC cores within the processing cluster.
This asynchronous execution paradigm enables intrinsic overlapping of computation and communication processes, which enhances throughput in scenarios where computation can proceed independently from communication results. This architectural advantage is especially pronounced in computation-intensive applications such as neural network training.
Despite these performance benefits, resource contention is a significant consideration. DMA engines are shared resources between computation and communication subsystems. This contention can cause throughput degradation for compute operations due to delayed DMA transactions between High Bandwidth Memory (HBM) and Scratchpad Buffer (SBUF), affecting both input tensor loading and output tensor spill-out for computation engines. Communication operations may also experience performance degradation due to time-sharing of DMA engine resources. Implementing optimal DMA prioritization strategies is critical for maximizing system performance in real-world conditions.
For more details, see the Neuron Runtime documentation and the Neuron Compiler Guide.
Overlap Between Compute and Communication#
The Neuron compiler enables concurrent execution of operations across the Neuron core and CC core through a sophisticated instruction scheduling mechanism. The compiler backend maintains separate scheduling queues for computation engines and communication streams, allowing independent instruction scheduling except where explicit dependencies exist. In theory, this design should enable optimal overlapping of compute and communication operations without manual intervention, similar to scheduling computational instructions across multiple computation engines. However, empirical analysis reveals suboptimal overlapping patterns in some scenarios.
For example, in dense Large Language Model (LLM) training that uses Tensor Parallelism (TP), Fully-Sharded Data Parallelism (FSDP), and Sequence Parallelism (SP), each network layer exhibits characteristic communication requirements:
TP AllGather: Precedes matrix multiplication to consolidate sharded activations.
TP ReduceScatter: Aggregates and re-shards the outputs.
FSDP AllGather: Required before each layer execution to gather sharded model parameters.
FSDP ReduceScatter: Needed during the backward pass for gradient accumulation.
Current compiler heuristics schedule FSDP AllGather operations collectively at the earliest possible execution point, as these operations depend only on subsequent computational operations within their respective layers. However, this strategy creates resource contention with critical TP communication operations, resulting in decreased end-to-end performance—even when Multi-stream CC capability is available for concurrent execution. A more efficient approach would proactively perform FSDP AllGather for a given layer during the execution of the preceding layer.
Similarly, FSDP ReduceScatter operations are typically scheduled at the end of the backward pass, just before optimizer execution, due to compiler memory optimization strategies. An alternative scheduling approach—placing each FSDP ReduceScatter operation within the subsequent backward layer—would enable better computational overlap and eliminate idle periods at the end of the backward pass.
For a deeper look at distributed training strategies, see the Neuron Distributed Training Guide.
Token Threading for FSDP#
To achieve optimal overlapping of CC operations, a novel dependency control mechanism called Token Threading for FSDP has been implemented. This experimental feature can be activated with environment variables:
For JAX frameworks:
NEURON_FSDP=1For NeuronX Distributed (NxD):
NEURON_NXD_FSDP_CC_MULTISTREAM=1
This mechanism uses a specialized Neuron PJRT compiler pass to identify operation patterns spanning TP and FSDP dimensions. It enforces precise execution ordering between CC operations by establishing synthetic data dependencies using a daisy-chain configuration of token tensors. Each token is a single-element tensor serving as a synchronization mechanism.
The resulting High Level Optimizer (HLO) instruction sequence demonstrates the dependency chain:
constant.45 = bf16[] constant(0)
all-gather.26 = (bf16[4096,8192]{2,1,0}, bf16[]) all-gather(param, constant.45), ...
...
get-tuple-element.6 = bf16[] get-tuple-element(all-gather.26), index=1,...
all-gather.25 = (bf16[896,8192]{1,0}, bf16[]) all-gather(param.2, get-tuple-element.6), ...
...
get-tuple-element.2 = bf16[896,8192]{1,0} get-tuple-element(all-gather.25), index=0, ...
dot.9 = bf16[4096,8192]{1,0} dot(maximum.14, get-tuple-element.2),...
...
get-tuple-element.7 = bf16[] get-tuple-element(all-gather.25), index=1, ...
reduce-scatter.8 = (bf16[128,8192]{1,0}, bf16[]) reduce-scatter(dot.9, get-tuple-element.7), ...
A token is extracted from the preceding CC operation and incorporated into the input tuple of the next CC operation, creating an explicit data dependency that enforces deterministic ordering. The Neuron compiler preserves this ordering during instruction scheduling but eliminates the token tensors from the final execution plan.
This implementation enables effective overlapping of FSDP CC operations with computational operations in adjacent network layers. Performance analysis confirms that FSDP AllGather operations for Attention layers successfully overlap with computation in preceding Multi-Layer Perceptron (MLP) layers, specifically in the execution window between TP AllGather and ReduceScatter operations.
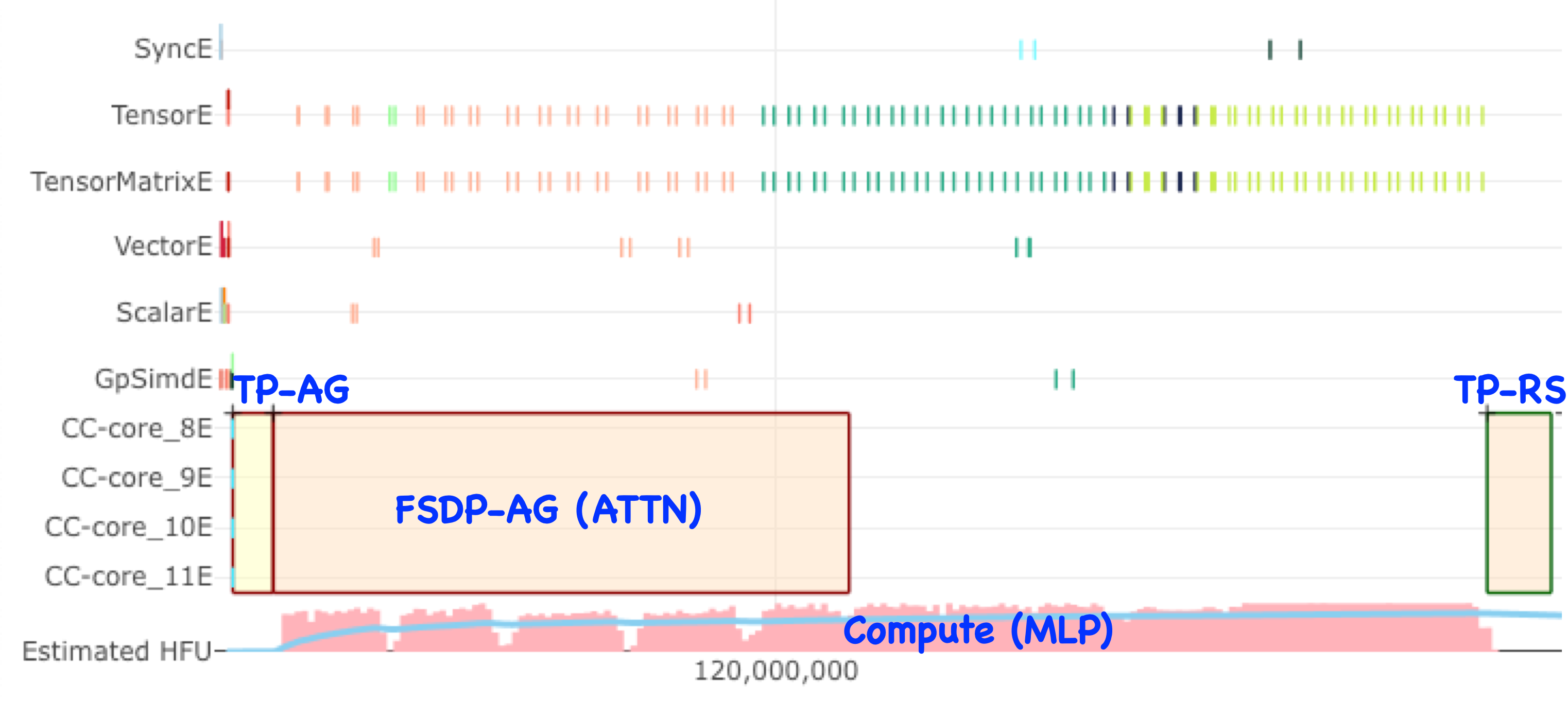
Image that shows how FSDP-AG operations for Attention layers successfully overlap with computation in preceding MLP layers.#
For more information on FSDP CC operations, see the Neuron Compiler Advanced Features.
Adjusting Static DMA Priority#
To address performance degradation caused by overlapping FSDP AllGather operations competing for DMA resources, a configurable static prioritization mechanism is provided through DMA packet size adjustment. DMA engines process descriptors from up to 16 DMA rings in HBM using a round-robin arbitration scheme. Arbitration transitions between rings only at packet boundaries. DMA rings with smaller packet sizes are more susceptible to resource starvation. Increasing packet size elevates processing priority.
The Neuron compiler generates PseudoDmaTrigger (PDMAT) instructions and descriptors in the NEFF.
The Neuron Runtime translates these into hardware WRITE operations and constructs hardware-compatible DMA rings.
The
NEURON_RT_DBG_DMA_PACKETIZATION_SIZEenvironment variable controls packet size during DMA ring construction. The default is 4 KiB, the empirically determined minimum for DMA/HBM efficiency. This parameter only allows increasing packet size to elevate priority.For PTC2 instructions,
NEURON_RT_DBG_CC_DMA_PACKET_SIZEcontrols packet size, with a default and maximum of 64 KiB. This parameter only allows reducing packet size to lower priority and only affects memory copy components of CC operations.
For systems with both TP and FSDP, optimal performance is achieved by prioritizing PDMAT for computational operations over FSDP CC operations:
NEURON_RT_DBG_DMA_PACKETIZATION_SIZE=65536
NEURON_RT_DBG_CC_DMA_PACKET_SIZE=4096
Although NEURON_RT_DBG_CC_DMA_PACKET_SIZE also affects critical TP collective communication operations, empirical analysis shows operational efficiency remains unimpaired.
The architecture supports additional DMA instruction types for dynamic transaction handling (DmaMemcpy, DmaIndirect, DmaTranspose), using the Descriptor Generation Engine (DGE) to generate DMA descriptors dynamically. The NEURON_RT_DBG_DMA_PACKETIZATION_SIZE parameter does not affect these DGE-based instructions. Enhanced dynamic DMA prioritization is under development.
See the Neuron Runtime Tuning Guide for more information.
Overlap Between Communications – Multi-stream CC#
Optimal system performance requires computation duration to be sufficient to fully mask communication latency. Partial communication masking can provide incremental benefits but may introduce secondary performance implications as seen in the figure below.
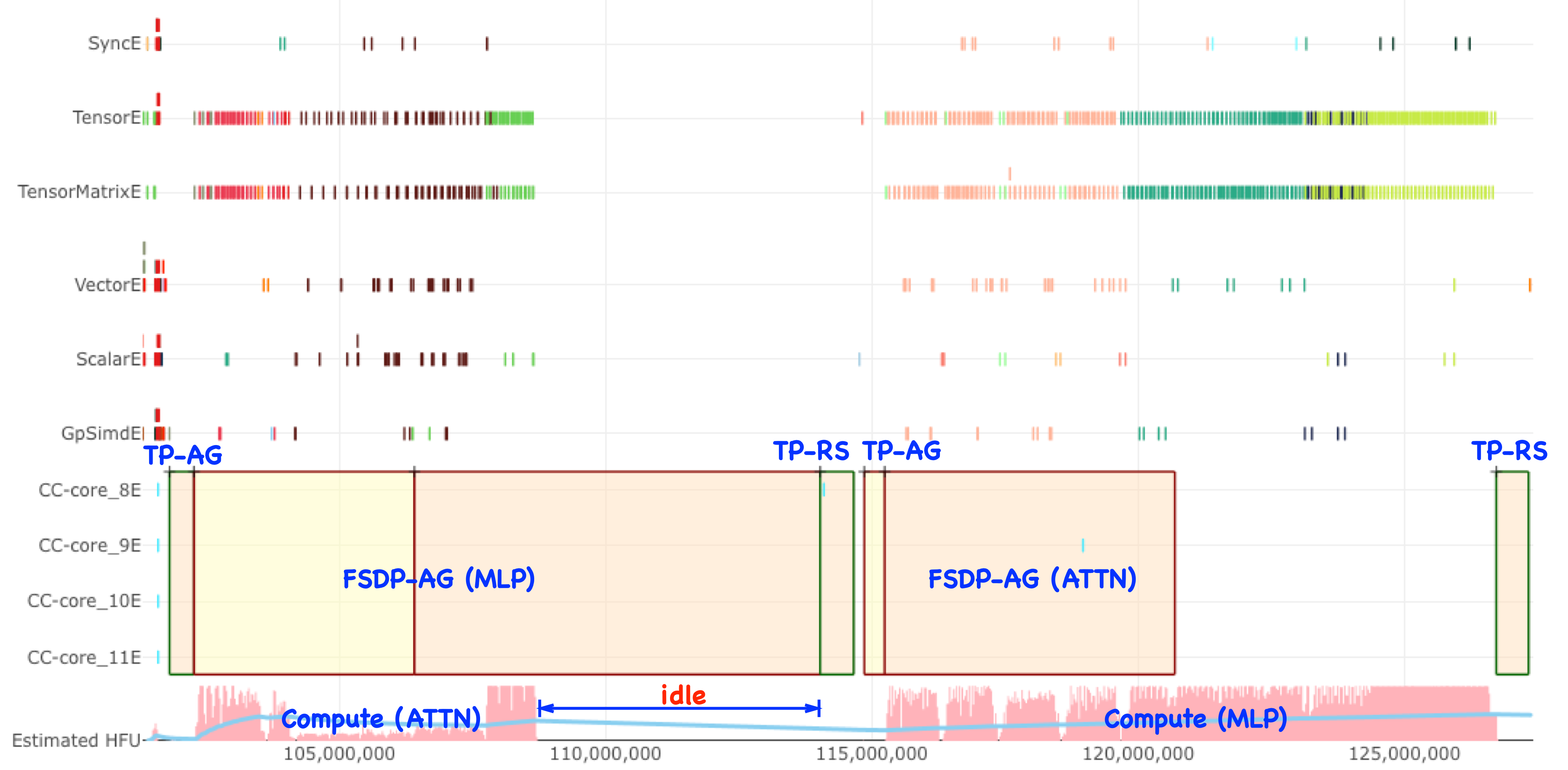
Image that shows idle compute resources due to cross-compute communication latency.#
In experimental configurations, FSDP AllGather operations gather weight parameters for Up, Gate, and Down projections in the next MLP layer. These operations are larger than those in the Attention layer, and the Attention layer’s computation is shorter. Extended FSDP AllGather operations can delay TP ReduceScatter operations, which could otherwise start immediately. If TP ReduceScatter could execute concurrently with FSDP AllGather, subsequent computations (such as Up and Gate projections) could begin earlier.
Multi-stream CC enables concurrent execution of communication operations using parallel communication resources. The hardware provides two CC cores per physical Neuron core. In TP×FSDP training, two physical Neuron cores are configured as a Logical Neuron Core (LNC2 mode), resulting in four CC cores per logical unit. Each CC core can manage a distinct communication stream, supporting up to four concurrent CC streams in LNC2 mode.
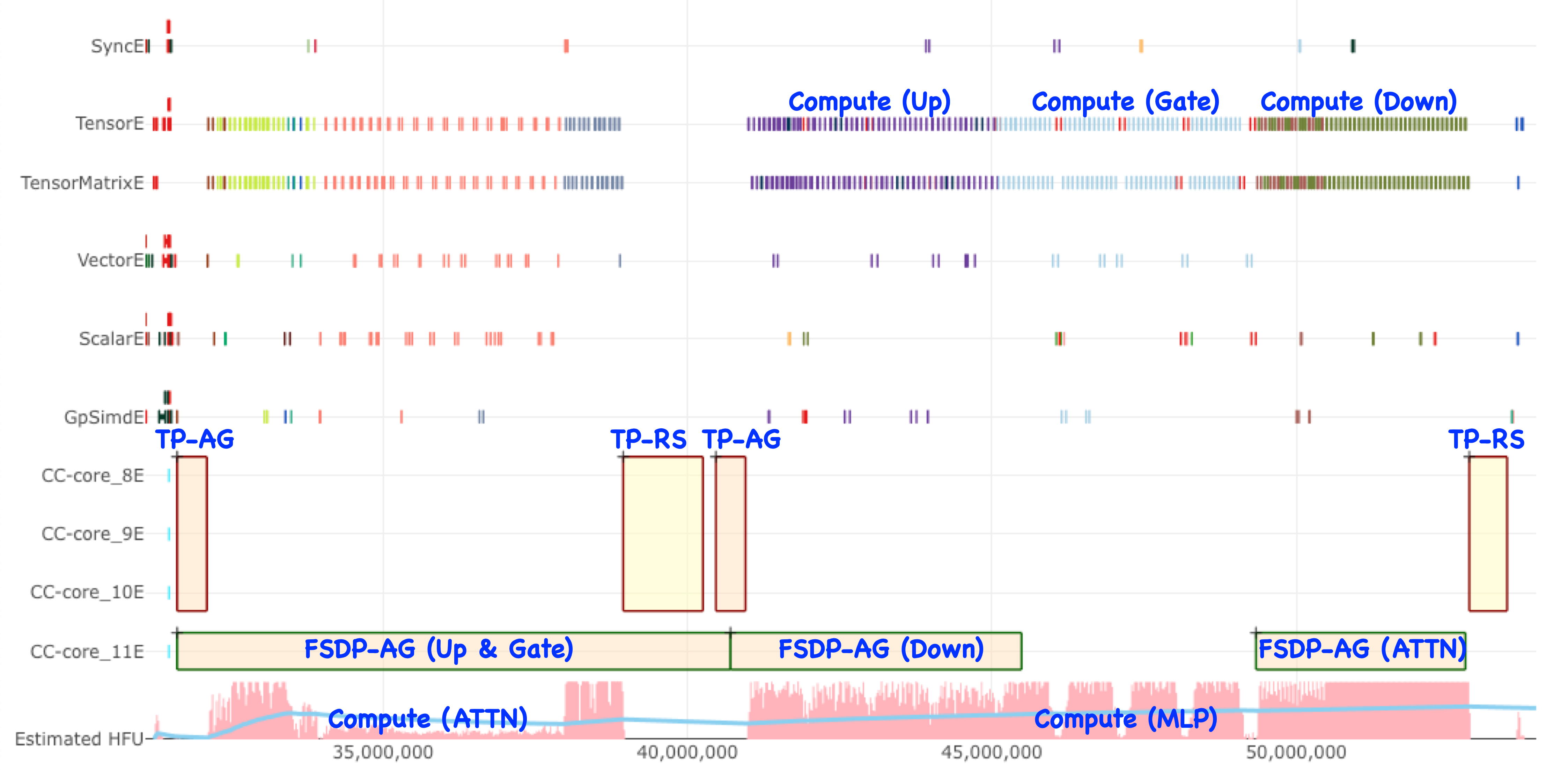
Image that shows efficient use of compute when effective overlapping of communication operations are enabled.#
With fewer streams than CC cores, each stream has exclusive access to a CC core, and surplus cores are allocated to stream 0.
Increased CC core allocation does not necessarily provide linear throughput gains. The benefit is greatest when communication operations use algorithms with multiple channels.
In reference implementations, optimal performance requires two streams: stream 0 for TP CC operations and stream 1 for FSDP CC operations.
To enable multi-stream CC in JAX, set these environment variables:
NEURON_FSDP=1
NEURON_FSDP_CC_MULTISTREAM=1
For NxD implementations, also set this environment variable:
NEURON_NXD_FSDP_CC_MULTISTREAM=1
The stream allocation mechanism is implemented in Neuron PJRT compilation passes, where CC stream identifiers (stream_id) are assigned to the frontend_attributes field of HLO instructions, using metadata tags from Token Threading for FSDP.
reduce-scatter.8 =
(bf16[128,8192]{1,0}, bf16[]) reduce-scatter(dot.9, get-tuple-element.7), ...
frontend_attributes={collective_type="tp_reduce_scatter",has_token="1",stream_id="0"}, ...
These configuration parameters are being incorporated into default settings in future releases, enabling automatic activation. More granular user-configurable options for stream allocation are also under development.
For more details, refer to the Neuron Distributed Inference Guide.
Adjusting Static DMA Priority (per Stream)#
DMA prioritization for TP CC operations is critical, as these operations directly block subsequent computation. They must not be delayed by concurrent FSDP CC weight prefetch operations. Since FSDP CC operations overlap with long computational sequences, they can be executed on a best-effort basis. The optimal DMA priority hierarchy is: TP CC ≥ PDMAT (compute) > FSDP CC.
The NEURON_RT_DBG_CC_DMA_PACKET_SIZE variable accepts comma-delimited values for individual adjustment of DMA packet sizes per communication stream:
NEURON_RT_DBG_DMA_PACKETIZATION_SIZE=65536
NEURON_RT_DBG_CC_DMA_PACKET_SIZE=65536,4096 # 65536 for stream 0, 4096 for stream 1
For more on DMA configuration, see the Neuron Runtime Advanced Configuration.
Weight Prefetch#
To overlap FSDP CC operations with computation from adjacent layers, FSDP AllGather operations are strategically relocated to preceding layers in both forward and backward passes. Similarly, FSDP ReduceScatter operations in the backward pass are relocated to subsequent layers. Large language models typically alternate Attention and MLP blocks. MLP layers have longer computation and larger weights, resulting in larger FSDP CC operations.
If all FSDP CC operations are shifted by one layer, Attention layers in the backward pass may be burdened with very large FSDP AllGather and ReduceScatter operations for adjacent MLP layers, exceeding their computational duration.
To balance communication and computation, additional configuration parameters enable precise control over the shifting distance for FSDP CC operations:
NEURON_FSDP_NUM_LAYER_EARLY_AG_SHIFT=1
NEURON_FSDP_NUM_LAYER_LATE_RS_SHIFT=2
These parameters enable differential shifting strategies for AllGather and ReduceScatter operations, optimizing the overlap pattern for each model architecture.
See the Neuron FSDP Optimization Guide for further details.
What’s Next?#
Dynamic DMA Prioritization#
Future implementations will introduce a dedicated field in DMA instructions to specify priority class, enabling dynamic DMA prioritization at the instruction level, including DGE instructions. This will allow developers to assign priority designations in HLO instructions, with the Neuron compiler generating instructions with appropriate priority class based on user tags and compiler heuristics. Beyond packet size adjustment, this approach will provide additional mechanisms for regulating relative priority among competing instructions.
For critical CC operations, the DGE will implement dynamic resource reallocation, temporarily relinquishing DMA engines occupied by inflight CC operations. This is especially beneficial for latency-sensitive scenarios, such as inference token generation, where CC operations are critical and often contend with weight prefetching from HBM to SBUF. Since these critical operations typically involve small data transfers, packet size adjustment may not be sufficient. Complete isolation of DMA engines during these operations can yield substantial improvements in end-to-end performance, even if it reduces overall DGE throughput.
For updates on upcoming features, see the Neuron SDK Release Notes.
Fine-grained CC#
Currently, TP CC operations cannot be effectively overlapped with computation due to strict data dependencies. Performance profiles show computational idle periods during TP collective communication operations. Two common patterns create these stalls:
dot(all-gather(x), y): Matrix multiplication cannot proceed until AllGather consolidates sharded activations across the TP dimension.reduce-scatter(dot(x, y)): Requires matrix multiplication to complete before reduction and redistribution.
These CC operations can be decomposed into more granular communication primitives—specifically, sequences of send/receive operations implemented with CollectivePermute operations. In the dot(all-gather(x), y) pattern, this allows partial matrix multiplication to begin with each received data segment while transmitting it to other ranks, rather than waiting for the full tensor. Similarly, reduce-scatter(dot(x, y)) can be restructured for progressive reduction and communication of partial results during ongoing computation.
This fine-grained CC approach is based on research from Google and is under development for future versions of the Neuron SDK.
For ongoing research and future directions, see the Neuron SDK Research Blog.
Read More#
This document is relevant for: Inf1, Inf2, Trn1, Trn2