
This document is relevant for: Inf2, Trn1
Generative LLM inference with Neuron#
Background#
Large Language Models (LLMs) generate human-like text through a process known as generative inference. Fundamentally, given an input prompt, generative LLM inference generates text outputs, by iteratively predicting the next token in a sequence.
These models typically take a sequence of integers as input, which represent a sequence of tokens (words/subwords), and generate a prediction for the next token to be emitted. Below is a simple example that illustrates this in code:
# Vocabulary of tokens the model can parse. The position of each token in the
# vocabulary is used as the token_id (an integer representing that token)
vocab = ["having", "I", "fun", "am", "learning", ".", "Neuron"]
# input token_ids: list of integers that represent the input tokens in this
# case: "I", "am", "having", "fun"
input_token_ids = [1, 3, 0, 2]
# The LLM gets a vector of input token_ids, and generates a probability-distribution
# for what the output token_id should be (with a probability score for each token_id
# in the vocabulary)
output = LLM(input_token_ids)
# by taking argmax on the output, we effectively perform a 'greedy sampling' process,
# i.e. we choose the token_id with the highest probability. Other sampling techniques
# also exist, e.g. Top-K. By choosing a probabilistic sampling method we enable the model
# to generate different outputs when called multiple times with the same input.
next_token_id = np.argmax(output)
# map the token_id back into an output token
next_token = vocab[next_token_id]
To generate entire sentences, the application iteratively invokes the LLM to generate the next token’s prediction, and at each iteration we append the predicted token back into the input:
def generate(input_token_ids, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # decode loop
output = LLM(input_token_ids) # model forward pass
next_token_id = np.argmax(output) # greedy sampling
if (next_token_id == EOS_TOK_ID)
break # break if generated End Of Sentence (EOS)
# append the prediction to the input, and continue to the next out_token
input_token_ids.append(int(next_token_id))
return input_token_ids[-n_tokens_to_generate :] # only return generated token_ids
input_token_ids = [1, 3] # "I" "am"
output_token_ids = generate(input_tokens_ids, 4) # output_token_ids = [0, 2, 4, 6]
output_tokens = [vocab[i] for i in output_token_ids] # "having" "fun" "learning" “Neuron”
This process, of predicting a future value (regression) and adding it back into the input (auto), is sometimes referred to as autoregression. For more details, Jay Mody’s GPT in 60 Lines of NumPy is an excellent writeup on GPTs (Generative Pre-trained Transformers).
Performance optimizations#
The sheer size of state-of-the-art LLMs, as well as the sequential nature of text generation, poses multiple challenges for efficient generative LLM deployment.
First, the model is typically sharded across multiple devices, in order to fit the model in device memory. This creates communication overhead and complexity among devices. Secondly, certain deployments have strict application-level latency bounds, thus requiring substantial latency optimizations. This is especially challenging, due to the sequential nature of token-by-token generation. Finally, generating one token at a time often leads to poor device utilization, due to low arithmetic intensity, which can be improved via batching (see What batch-size should I use?).
The Neuron SDK provides several built-in optimizations, allowing you to extract optimal performance when deploying LLM models, including:
KV-caching:#
The transformers-neuronx library implements KV-cache optimization, which saves compute resources by reusing previously calculated SelfAttention key-value pairs, instead of recalculating them for each generated token.
To illustrate this concept, see the inner workings of the MaskedSelfAttention operator in the figure below.
At each token generation step, the Query vector of a single current token is multiplied by the Key vectors of all previous tokens in the sequence to create attention scores and these scores are further multiplied by the Value vectors of all previous tokens.
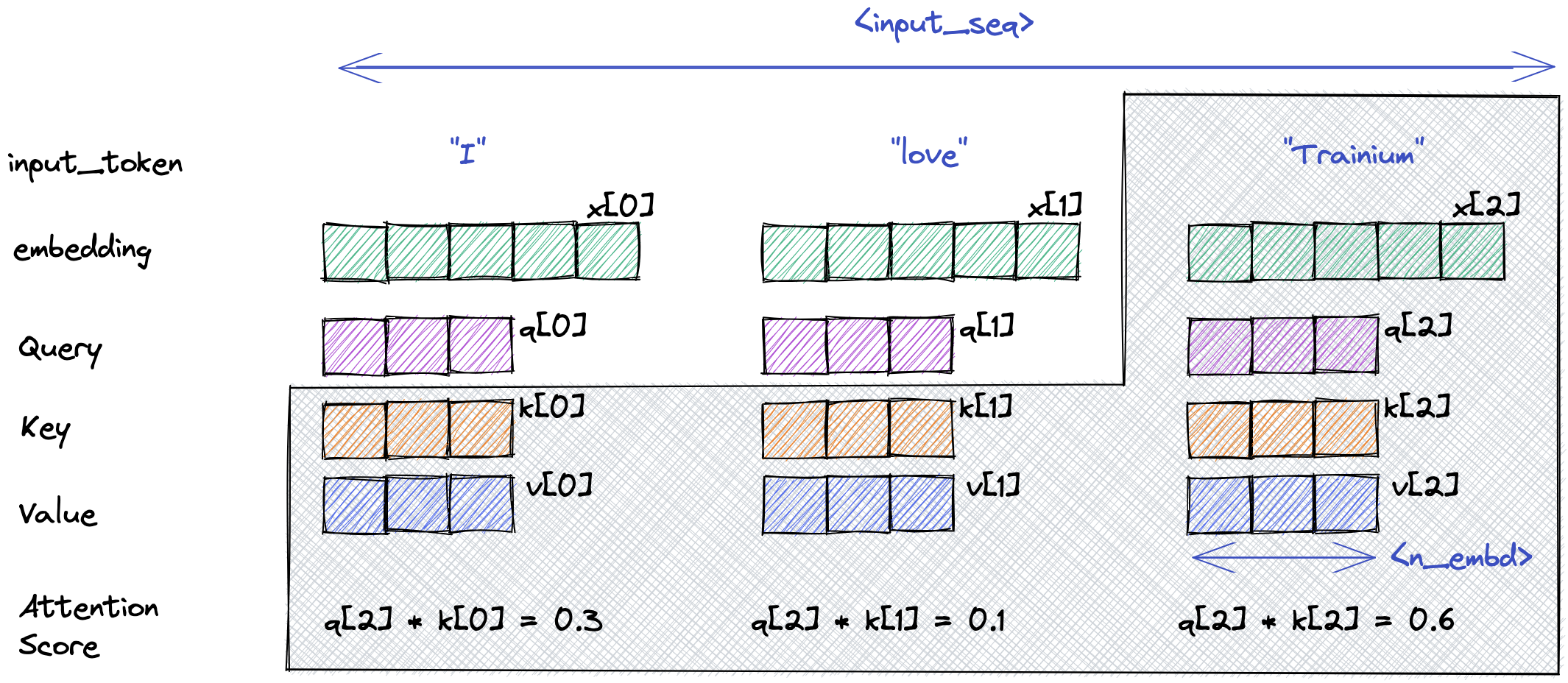
The core idea behind this optimization is that instead of re-computing the Key and Value vectors for all previous tokens at each token generation step, Neuron can perform only incremental computation for the current token and re-use previously computed Key/Value vectors from the KV-cache. The Key/Value vector of the current token is also appended to the KV-cache, for the next token generation step.
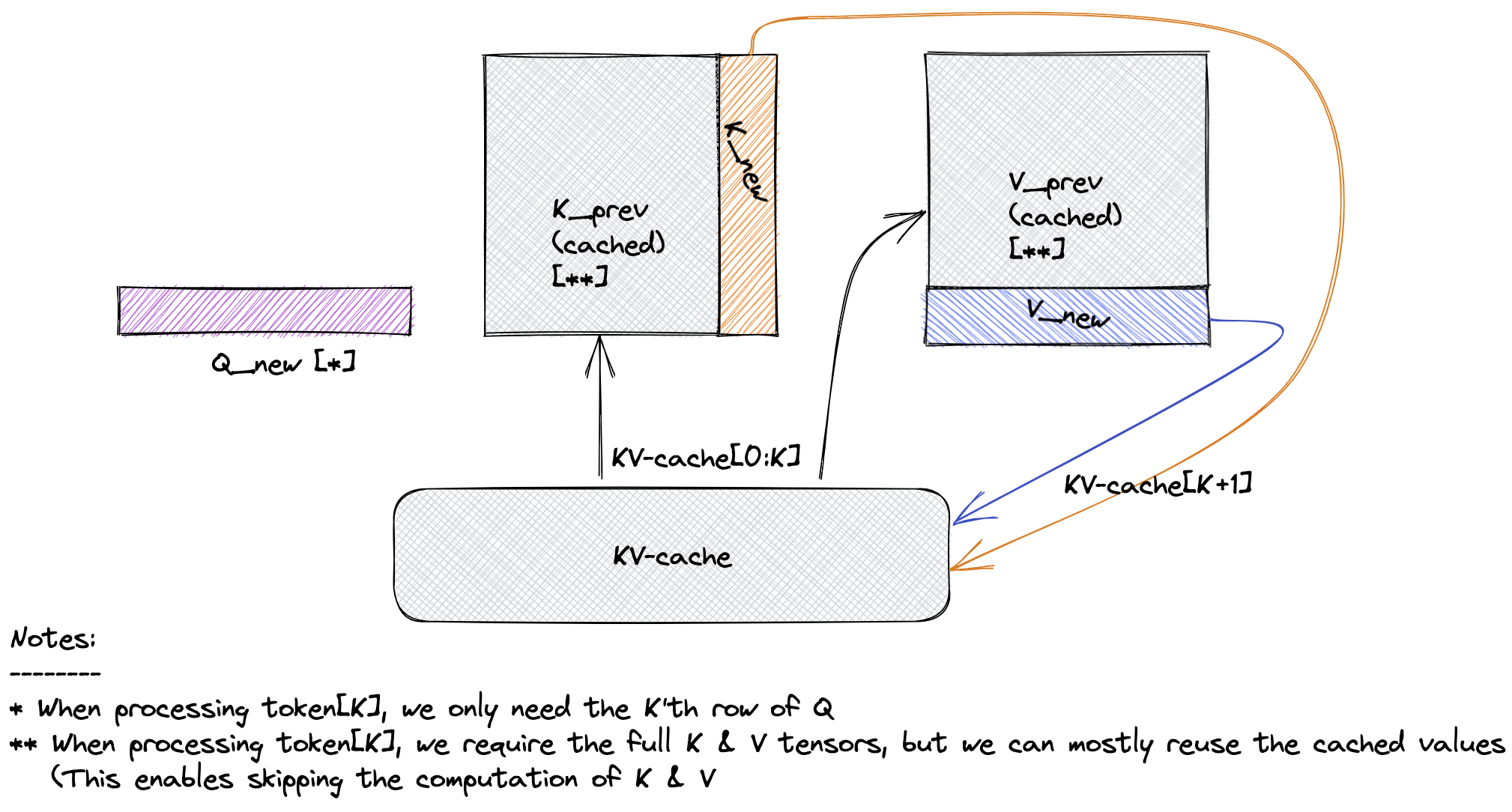
Note that the first token in the output sequence is unique in two ways:
No KV-cache is available at this point.
Neuron needs to compute the entire KV-cache for <input_len> tokens (the input prompt), rather than one incremental KV-cache entry.
This means that first-token latency is typically higher than the following tokens.
Model sharding:#
Neuron enables you to shard the model across devices via Tensor Parallelism, Pipeline Parallelism (coming soon), or a combination of the two (coming soon).
Tensor Parallelism shards each layer across multiple devices, enabling you to achieve the optimal latency.
Pipeline Parallelism places different layers on different devices and creates a pipeline between them (as the name suggests) and is useful mainly when optimizing throughput and/or cost-per-inference.
To find the optimal Tensor/Pipeline parallelism configuration for your model, see the Model partitioning section.
Computation/communication overlap:#
The Neuron compiler automatically fuses Collective Communication primitives (e.g., AllReduce) with the following computation (e.g., GEMM) in the compute graph. This helps minimize any overhead caused by sharding the model across devices.
Compact data-types:#
Neuron supports INT8 and FP8 (coming soon), which can significantly reduce the model’s memory bandwidth and capacity requirements. This is especially useful for Generative LLM inference, which is typically memory-bound. Therefore, using a compact data-type can improve the overall LLM inference performance with lower latency and higher throughput.
Bucketing:#
The transformers-neuronx library automatically uses bucketing to process the input prompt and output tokens. Bucketing makes it possible to handle variable sequence lengths, without requiring support for dynamic shapes. Using multiple progressively larger buckets helps minimize the portion of the KV-cache that needs to be read for each token.
Model partitioning#
How many NeuronCores do I need?#
Transformer models are typically defined via a hyper-parameter configuration, such as the following:
{
"n_vocab": 50257, # number of tokens in our vocabulary
"n_ctx": 2048, # maximum possible sequence length of the input
"n_embd": 9216, # embedding dimension (determines the "width" of the network)
"n_head": 72, # number of attention heads (n_embd must be divisible by n_head)
"n_layer": 64 # number of layers (determines the "depth" of the network)
}
To determine the number of NeuronCores needed to fit the model, perform the following calculation:
weight_mem_footprint = 12 x <n_layer> x <n_embd>^2 x <dtype-size>
KV_cache_mem_footprint = <batch-size> x <n_layer> x <n_ctx> x <n_embd> x 2 x <dtype-size>
# <dtype-size> is 2 for BF16/FP16, or 1 for FP8/INT8
mem_footprint = weight_mem_footprint + KV_cache_mem_footprint
And from here, determining the number of NeuronCores is straightforward:
num_neuron_cores = ceil_to_closest_supported_size (mem_footprint / <NC-HBM-capacity>, <instance-type>) # 16GiB per Inferentia2/Trainium1 NeuronCore
For example, when running OPT-66B on Inf2, with a batch-size of 16, the number of required NeuronCores can be computed as follows.
# OPT-66B example (BF16, Inf2)
# n_layer=64, n_ctx=2048, n_embd=9216, batch=16
weight_mem_footprint = 12 x 64 x 9216^2 x 2 = 121.5 GiB
KV_cache_mem_footprint = 16 x 64 x 2048 x 9216 x 2 x 2 = 72 GiB
mem_footprint = 121.5GiB + 72GiB = 193.5 GiB
num_neuron_cores = ceil_to_closest_supported_size (193.5GiB / 16GiB, Inf2)
= ceil_to_closest_supported_size (12.1) = 24
## Currently, the Neuron runtime supports tensor-parallelism degrees 2, 8, and 32 on Trn1
## and supports tensor-parallelism degrees 2, 4, 8, 12 and 24 on Inf2.
Use the Neuron Calculator to compute the number of cores needed for a custom hyper-parameter configuration.
Which parallelism technique should I use?#
Tensor parallelism improves latency, at the expense of increased intra-layer communication. Thus, as a general rule, it is recommended to use the smallest tensor parallelism degree that meets your latency requirement and then use pipeline/data parallelism from that point on.
If latency is not a major concern in your application (e.g., model evaluation) and the primary goal is to maximize throughput (i.e., minimize total cost per token), then it is most efficient to use pipeline parallelism and increase the batch-size as much as possible.
What batch-size should I use?#
Due to the serial token generation nature of generative LLM inference, this workload tends to be extremely memory bound. This means that throughput (and thus cost per inference) improves significantly by batching.
As a general rule, we recommend increasing the batch-size to the maximum amount that fits within the latency budget (up to batch=256. A larger batch-size typically does not help with performance.)
Note that the KV-cache grows linearly with the batch-size and can grow until it runs out of memory (typically referred to as OOM). If the latency budget allows, we recommend increasing the batch-size to the maximum value that does not result in OOM.
Users may also consider pipelining the model beyond what is necessary to fit model parameters / KV-cache on devices, in order to free up device-memory space and thus allow the batch-size to increase without causing OOM issues.
This document is relevant for: Inf2, Trn1