Trainium Architecture
This document is relevant for: Trn1, Trn1n
Trainium Architecture#
At the heart of the Trn1 instance are 16 x Trainium devices (each Trainium include 2 x NeuronCore-v2). Trainium is the second generation purpose-built Machine Learning accelerator from AWS. The Trainium device architecture is depicted below:
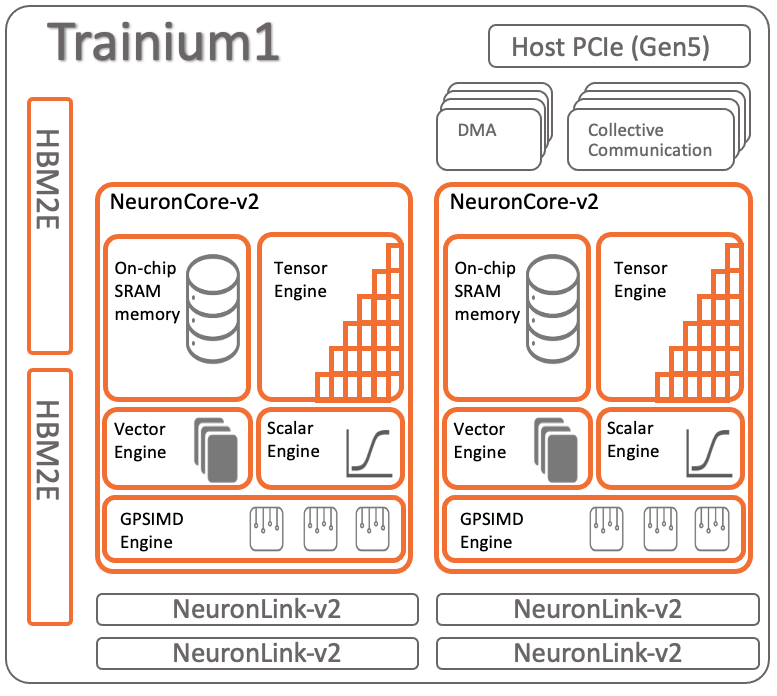
Each Trainium device consists of:
- Compute:
2x NeuronCore-v2 cores, delivering 420 INT8 TOPS, 190 FP16/BF16/cFP8/TF32 TFLOPS, and 47.5 FP32 TFLOPS.
- Device Memory:
32GB of device memory (for storing model state), with 820 GB/sec of bandwidth.
- Data movement:
1 TB/sec of DMA bandwidth, with inline memory compression/decompression.
- NeuronLink:
NeuronLink-v2 for device-to-device interconnect enables efficient scale-out training, as well as memory pooling between the different Trainium devices.
- Programmability:
Trainium supports dynamic shapes and control flow, via ISA extensions of NeuronCore-v2. In addition, Trainium also allows for user-programmable rounding mode (Round Nearest Even Stochastic Rounding), and custom-operators via the deeply embedded GPSIMD engines.
This document is relevant for: Trn1, Trn1n